Context Cost · Research
Context Minimization Principle
A framework for software design as the discipline of reducing context acquisition cost — for humans and AI agents alike.
Exported from contextcost.dev/cmp. Draft chapters are not included.
Chapter 1
Reliable Coding Agents Need Better Codebases
Better models and better harnesses matter. But agents also need codebases where the right context is cheap to find, trust, and use.
TL;DR
How can we make coding agents more reliable in real codebases?
The common answers are better models and better harness engineering. Both matter, and both are improving fast. But they are not the whole answer. The codebase itself also determines how reliably an agent can work.
AI has made code cheaper to produce, but it has not made software cheaper to change correctly. The hard part of real modification is not typing the patch. It is acquiring enough context to know what the patch must preserve, where related decisions live, and whether the change is complete.
This hidden cost is context cost. Human teams have always paid it through seniority, onboarding, code review, and tribal knowledge. Coding agents make it visible, they fail when the required context is implicit, scattered, unreliable, or hard to discover.
The Context Minimization Principle reframes software design around this cost: for the modifications a system must realistically support, a design is better when the sufficient context required for correct modification is cheaper to acquire.
A programmer picks up a bug. The actual fix is small: maybe two lines, one condition, a missing field in a serializer, a wrong assumption in a background job, or an edge case in a permission check. But the patch does not take two minutes. It takes three days.
The first day is spent reconstructing how the system is supposed to behave and confirming that the bug is really a bug. The second is spent following the call chain, reading tests, checking old pull requests, and asking why the logic exists in three different places. The third is spent building enough confidence that the change is complete and will not break something somewhere else. When the commit finally lands, the diff looks almost trivial. The work was not.
This gap has a name: context cost.
Context cost is the cost of acquiring enough context to modify a system correctly. Writing the patch itself — editing files, changing tests, committing the diff — is the small, visible part. The rest is context cost: understanding what behavior is intended, where the relevant decisions live, which assumptions must be preserved, which other places must change together, and where the boundaries of the change actually are. In mature codebases, this is usually most of the work.
Experienced programmers feel this tax even without naming it. They call it onboarding cost, ramp-up time, system familiarity, legacy complexity, technical debt, tribal knowledge. Each phrase captures part of the pain, but none of them names the underlying cost directly. The hidden tax is context cost.
For decades, human programmers have paid this tax so routinely that we stopped seeing it. We call it experience. We call it seniority. We call it knowing the codebase. A senior engineer can often make a change safely not because the system is simple, but because years of accumulated modification context have been cached in their head.
Then AI coding agents arrived, and context cost became visible.
Agents make the bill visible
An AI coding agent does not experience a codebase the way a long-tenured human engineer does. It does not remember the hallway conversation from two years ago. It does not know that the billing job is special because a large customer depends on an undocumented export format. It does not remember the incident that made the team afraid to touch a certain module. It does not infer, from organizational memory, that two similar-looking code paths must never be merged.
An agent can search, read, call tools, run tests, and generate patches very quickly. But what it knows must be supplied, retrieved, or encoded in explicit artifacts. What is not reachable is, for practical purposes, absent.
This is why agentic programming produces such a strange mix of power and fragility. The agent can write competent code: implement a function, update an API, generate tests, or refactor a file faster than most humans. But in a real codebase, it may still miss the one place where the same decision is duplicated. It may trust a boundary that is nominal but not meaningful. It may update the obvious test while missing the invariant that was never written down.
When this happens, the easy explanation is that the model is not smart enough. That explanation is too shallow.
Current agents have many limitations, and future agents will become much stronger. Context windows will grow. Retrieval will improve. Tool use will become more reliable. Agents will learn better strategies for navigating repositories, interpreting tests, and asking for missing information. But the underlying problem will not disappear, because correct modification still requires sufficient context.
A larger context window changes how much information can be carried; it does not automatically decide which information is relevant, trustworthy, complete, or sufficient. A smarter agent can search better, but it still needs something to search through. It can reason more deeply, but it still needs reliable signals from the system.
A more capable AI does not abolish context cost. It raises the level at which context cost must be managed.
This is the real significance of AI coding agents. They are not important to software design merely because they can write code. They are important because they turn an indirect tax into a direct one — a cost that human teams have always paid quietly is now charged in plain sight.
We can now see which files an agent retrieved, where it searched, which tests failed, which edits it missed, and how many attempts it needed before the patch became correct. These traces are not a perfect measurement of design quality. They depend on the agent, the prompt, the tools, and the task. But they reveal something that used to be hidden inside human cognition: how much context a correct modification actually requires, and how hard that context is to acquire. The agent is not failing at coding. It is failing at context acquisition.
When an agent fails this way, it is often showing us the same tax human engineers have been paying all along.
This is not an AI problem
It is tempting to treat agent failures as a temporary weakness of today’s models. That would miss the deeper lesson.
When an agent modifies one field but misses the schema migration, the validator, the UI form, the analytics query, and the test fixture, the problem is not only that the agent failed to search widely enough. The system encoded one decision across multiple places without making the relationship reliably discoverable.
When an agent reads an interface but still has to inspect three implementations to understand what the method really means, the problem is not only that the agent lacks judgment. The boundary did not express a trustworthy contract.
When an agent breaks behavior because the key invariant existed only in a senior engineer’s memory, the problem is not only that the agent lacked access to that memory. The system depended on implicit context to preserve correctness.
Humans suffer from the same conditions, but they have one form of access agents typically lack: information that was never written down. A human engineer can ask the teammate who built the system, remember a hallway conversation about why a job is special, or recall the incident that made the team quietly stop touching a module. The durable asymmetry is access to context that lives only in heads and conversations, not in files.
This compensation is powerful, but it has a cost. It makes onboarding slow. It makes refactoring frightening. It makes review depend on the right person noticing the right omission. It makes teams afraid to change old modules. It makes “simple” tasks expand into days of investigation. It makes productivity uneven, concentrated in the few people who have cached enough context in their heads.
For humans, the pain is diffuse. It appears as hesitation, fatigue, long ramp-up, vague risk, and a general sense that the system is hard to change. Agents make the pain sharper. They turn invisible context cost into visible failure.
AI did not create the context problem. It made the bill impossible to ignore.
Software is made of modifications
To understand why this matters, we need to step back from AI. Software engineering is often pictured as two phases — development, where the system is built, and maintenance, where it is changed — as if writing new code and modifying existing code were different jobs. The split is a fiction. From the second commit onward, every change lands on a system that already exists. Modification is not what happens after development; it is development itself.
Adding a feature modifies the current system. Fixing a bug modifies behavior. Refactoring modifies structure while trying to preserve behavior. Reviewing a pull request evaluates whether a modification is safe. Testing checks whether a modification preserved the intended constraints. Useful software is not written once. It lives by changing.
If every change is a modification, and every modification has a context cost, then naturally we want that cost to be smaller. Where decisions live, which boundaries can be trusted, what is written down and what is left implicit — all of these shape how expensive the next modification will be. Software design is the name for the choices behind them.
We usually describe good design with words like beautiful, elegant, or clean. These words point at something real — well-designed systems do feel different to work with — but they are aesthetic reactions, not explanations. The underlying factor they gesture at, without ever naming, is how cheaply the next modification can acquire the context it needs.
A design is good when it makes realistic future modifications easier, safer, and more reliable. A design is bad when it forces the modifier to search too widely, follow too many unreliable paths, or depend too heavily on implicit knowledge before making a correct change.
A small module can be hard to modify if its behavior hides in configuration and framework magic; a large system can be easy if its decisions are well bounded and its tests make the important assumptions executable. The difficulty of changing a codebase is not set by how much code it has, but by how expensive it is to acquire enough context to change it correctly.
The Context Minimization Principle
This is the idea behind the Context Minimization Principle, or CMP.
For the modifications a system must realistically support, a design is better when the sufficient context required for correct modification is cheaper to acquire.
CMP is not a new aesthetic. It is a way to name the trade-off software engineers have always been making. A boundary is useful when it lets us stop reading. A test is useful when it preserves a behavioral fact we should not have to remember. An architecture is useful when it tells us where a decision should live. A convention is useful when it turns search into navigation.
These practices look different on the surface, but underneath they do the same kind of work: they make the context required for future modification cheaper to acquire.
This also explains why they fail. A boundary that cannot be trusted adds indirection without reducing understanding. An architecture that no longer predicts where decisions live becomes ceremony. An abstraction built for a future that never arrives becomes over-engineering. A convention that exists only in someone’s head becomes tribal knowledge.
CMP does not remove judgment. It sharpens the question. Instead of asking whether code is clean, simple, or elegant in the abstract, we can ask whether this design makes the context required for realistic modifications cheaper to acquire.
That question is small enough to use in practice and large enough to connect many old debates. It is also enough for a first principle. The point of CMP is not that every design decision can already be measured with a perfect number. The point is that software design has always lacked a shared currency for its trade-offs. Context cost is that currency.
The work that does not get cheaper
AI will write most of the code. That part is no longer a question — it is already happening on routine changes and will spread to harder ones. Whether the timeline is two years or ten does not change the direction. The cost of producing code is collapsing.
The new question is how to turn that cheapness into reliable systems quickly. Producing code is not the same thing as building a system — each batch of cheap code still has to land on a codebase that can absorb it without losing coherence. Which decisions a change must touch, which assumptions it preserves, which boundaries hold, which tests carry the important constraints — all of these decide whether AI’s speed becomes reliable systems or a faster mess. The faster code production gets, the more design skill matters.
Software design has always been valuable, but it has been hard to argue for. Beautiful, elegant, clean, simple — these are aesthetic claims, and aesthetic claims tend to lose in rooms where shipping is on the other side. CMP changes that. It replaces the aesthetic question with one a team can actually argue about: does this design make context cheaper for the modifications the system will have to support? That question is small enough to apply to a single pull request, large enough to defend an architectural call, and grounded enough that it does not dissolve into preference.
CMP gives design a question that has an answer.
That answer is rarely a precise number. But it is concrete enough to evaluate against and to lose a debate to. Design stops being something senior engineers gesture at and becomes something teams can reason about.
For individual programmers, this changes what is worth practicing. The established design principles and patterns — SOLID, DDD, clean architecture, etc. — do not become less valuable; each of them is a tested answer to manage context cost. Beyond the principles, one habit compounds: notice the context you are silently carrying while you make a change — the assumption you held in your head, the dependency you remembered, the prior decision you trusted without re-deriving — and push as much of it as possible into the artifact, so the next modifier does not have to rediscover what you already worked out. It is a small habit, but over time it is how good design stops being an abstract discipline and becomes a daily reflex.
The future does not bypass context
One possible objection is that future AI may solve this problem automatically. Perhaps agents will become so capable that they can read the whole codebase, infer the architecture, reconstruct the missing decisions, and make correct changes without humans designing for context.
Perhaps they will. But that would not make CMP irrelevant. It would mean the agent has learned to perform context acquisition more effectively. More intelligence does not remove the need for context management. It changes the form of context management.
A future AI might invent better ways to organize software than the patterns we use today. It might generate new indexes, maintain living documentation, derive tests from observed behavior, or continuously map decision relationships across a codebase. It might make context acquisition cheaper in ways we have not yet imagined. But whatever those mechanisms turn out to be, the software they produce will still be beautiful, clean, and elegant in a way we can now explain rather than just feel: organized so that whoever reads it next — a programmer or an agent — needs less context to understand it and to change it correctly.
The bill is on the table
Programmers have always known that some systems are easier to change than others. We know the feeling of a codebase where the next step is obvious: the boundary is clear, the test tells us what matters, the naming leads us to the right place, and the architecture narrows the search.
We also know the opposite feeling: every change opens another file, every rule has another exception, every abstraction leaks, every test is either brittle or irrelevant, and no one is sure where the real decision lives.
That difference is not a matter of taste. It is the central economic fact of software work: software must change, and every correct change requires sufficient context.
Good software design is the discipline of making future modification context cheaper to acquire.
The hidden tax has always been there. AI did not invent it. AI exposed it. Now that the bill is on the table, we can start designing against it — and software design stops being a sensibility a few engineers happen to have, and starts being a discipline a team can build.
Part I — Foundations
Chapter 2
Software Is Made of Modifications
Why software development is better understood as continuous modification rather than one-time creation.
Pick any software team on any ordinary day, and watch what they are actually doing.
Alice is adding an “export to CSV” button. She opens the controller, the service layer, the Excel builder, the permission checker, and three i18n files. Each file already exists; her work is to thread a new path through them without breaking the existing ones.
Bob is fixing a production bug. A discount calculated wrong for customers in a specific region. He traces the logic backward through a PricingService, a DiscountPolicy interface, a strategy factory, and a feature-flag check, until he finds a three-year-old workaround that no one remembers writing. He changes one condition and runs the test suite, hoping nothing else depended on the old behavior.
Claire is reviewing a pull request. The diff touches fourteen files, but she notices that every change is the same thing: a field renamed from clientId to customerId. The author did a find-and-replace. She approves, but makes a mental note: this field is now scattered across the codebase in a way that no single abstraction owns.
Dave is refactoring the payment module. He extracts a shared validator, inlines a one-caller abstraction, and splits a 400-line service into three focused units. Every commit must be behavior-preserving, so he runs the same test suite after each step, watching for any assertion that breaks.
Different people. Different tasks. Same underlying activity: modification.
The Fiction of Development vs. Maintenance
The traditional distinction between software “development” and “maintenance” is a project-management fiction. It may help with budgeting, but it obscures the essential fact of programming work: once a codebase exists, almost every subsequent engineering act is an act of modification.
This fiction causes two concrete harms.
The first is resource misallocation. When “development” is treated as a one-time capital expenditure, teams are incentivized to ship fast and defer structural concerns. Design debt accumulates not because engineers are careless, but because the accounting framework tells them that “maintenance” is a future phase with a future budget. The code shipped in “development” becomes the code modified in “maintenance” — and the design decisions made under ship-fast pressure become the context tax paid by every future modifier.
The second is cognitive fragmentation. The industry trains engineers to see feature work as creation, bug fixes as repair, and refactoring as cleanup — three different activities requiring three different mindsets. But the structure underlying all three is identical. A feature adds behavior by modifying existing code. A bug fix corrects behavior by modifying existing code. A refactor preserves behavior by modifying existing code. The surface differences are real — intent, urgency, scope — but the engine is the same: find where to change, understand what to preserve, decide what to edit, confirm the change was correct. When we treat these as separate disciplines, we lose the ability to see their shared cost structure.
In practice, the first public release is treated as the boundary between development and maintenance, and not without reason. Release is a real event: users depend on the system, data accumulates, integrations form around existing behavior, and operational guarantees begin to matter. But these changes do not turn creation into a different activity called upkeep. They add constraints — user data, backward compatibility, migrations, deprecation cycles, operational risk — to the same modification stream. Every such constraint is more context a modifier must acquire to be confident the change is safe. Release does not change what modification is; it increases the context cost of doing it correctly.
Extension Is Still Modification
At this point, an objection is likely to surface. The Open/Closed Principle — one of the most enduring ideas in software design — explicitly tells us that modules should be open for extension, but closed for modification. If the industry’s own design canon treats extension and modification as distinct, isn’t the claim that “everything is modification” flattening a distinction that matters?
It is not. OCP draws a line between two strategies for making a change, not between two kinds of activity. When you add a new payment method by implementing a PaymentStrategy interface and registering it, you have not avoided modifying the system. The system’s behavior before that change and after it are different. An invoice that would have been paid one way is now paid another. You have modified the system — you have just done so by adding code in a new location rather than rewriting code in an existing one.
This is not a semantic trick. It is the entire point of OCP. The principle does not claim that extension is not modification. It claims that, for certain classes of change, a design that lets the modifier add rather than rewrite makes the modification cheaper. The modifier does not have to understand the internals of the existing payment pipeline to extend it. The existing code is not touched, so the modifier does not have to verify that existing behavior was preserved — the mechanism of extension preserves it by construction. The context required for the change is smaller.
Read this way, OCP is not evidence that extension is different from modification. It is evidence that good design reduces the cost of modification — and one of the most effective ways to do that is to make certain modifications expressible as additions rather than rewrites. The goal is still modification. The strategy has just been optimized.
Software Evolves Through a Stream of Modifications
Software is not produced as a single uninterrupted act of creation. It accretes through a sequence of changes to a partial system. And the expectations those changes must satisfy are themselves constantly shifting.
The reasons are familiar enough: requirements shift, domains evolve, integrations change, and usage reveals assumptions that were wrong.
A living system is never designed for one isolated future. It must survive a stream of modifications whose exact direction, frequency, and shape remain uncertain. This is not a failure of requirements gathering. It is the normal condition of software that remains useful: it must keep adapting to change.
Design’s True Purpose
Because change is the defining condition of useful software, modifiability is not merely one quality attribute among many. It is the problem software design exists to address.
Design, as a discipline distinct from making code execute, is the practice of making future modifications simpler, safer, and more reliable. The design principles that have survived decades of practice — information hiding, DRY, SOLID, testing — all earn their keep on this single standard. The payoff of good design is not deferred to a mythical maintenance phase; it accelerates the very next modification, by ensuring the modifier has exactly the context they need to make the change safely.
Chapter 3
The Cost of Modification
Required context, explicit and implicit knowledge, and why context cost is the shared currency of software engineering.
The software industry has long championed “maintainability” and “readability” as primary design goals. Yet neither is an end in itself. We maintain and read code for one operational purpose: to modify it. A developer does not study a codebase for passive comprehension; they read to make decisions about what to alter, what to preserve, and how to safely navigate constraints. Even debugging, reviewing, and testing are not distinct disciplines, but supporting operations within this broader modification pipeline. They exist to establish whether a change can be safely made, where it belongs, and whether it was executed correctly.
Information Completeness
To execute a modification correctly, a developer or AI agent must achieve information completeness. They cannot change a system reliably while guessing its constraints. They must acquire a sufficient set of facts to perform the change and preserve intended behavior. We call this sufficient information set the required context of a modification.
Context is the sum of all knowledge required to execute a change. This knowledge fundamentally takes two forms: explicit and implicit.
- Explicit context is information formally encoded in written artifacts—the source code itself, schemas, tests, and documentation.
- Implicit context is the unwritten information a developer must hold in their head—runtime behaviors, hidden global states, historical decisions, tribal knowledge, or the invisible side effects of a framework.
Defining Context Cost
Acquiring this required context is the central operational burden of modification. Recall the four steps of modification from the previous chapter: find where to change, understand what to preserve, decide what to edit, and confirm the change was correct. The effort spent moving through these steps is not determined merely by the sheer amount of information you need to read. It is determined by the cost of acquiring that information with enough confidence that your context is complete.
This includes the size of the context, the spread of the context, the traversal needed to reach it, and the reliability of the paths by which it can be found. The anxiety developers feel in poorly designed systems comes from the lack of a reliable stopping point—you can never be entirely sure you have found all the constraints or ripple effects; you just stop when you run out of time or patience, and hope the test suite catches what you missed.
We call this operational burden Context Cost: the cost of acquiring sufficient context for correct modification. Context cost includes not only the size of the required context, but also how that context is reached, how widely it is spread, and how reliably the modifier can know that the acquired context is complete.
The Currency of Design
If software development is a continuous stream of modifications, and every modification requires acquiring sufficient context, then the cost of that acquisition is the shared currency of software engineering.
The purpose of software design becomes very concrete: good design minimizes context cost. It is not about adhering to abstract aesthetics, following principles to the letter, or pursuing “cleanliness” for its own sake. It is about making the required context for a realistic modification cheaper, safer, and more reliable to acquire.
When we stop arguing about whether a design is “elegant” and start asking how much context a future modifier will need to carry, design debates lose their dogma. We stop judging code by how it looks, and start judging it by the operational burden it imposes on the next person who has to change it.
Chapter 4
The Context Minimization Principle
The formal statement of CMP and the four constraints that turn it from a slogan into a comparative frame for software design.
If software development is a continuous stream of modifications, and good design minimizes the cost of acquiring sufficient context for those modifications, then this intuition deserves a name. We call it the Context Minimization Principle (CMP). Made precise, it becomes a principle one can argue with:
For the modifications a system must realistically support, a design is better when the sufficient context required for correct modification is cheaper to acquire.
Four constraints do the real work.
Realistically Support
CMP does not rank designs in the abstract. It evaluates them against the plausible stream of future modifications a system must support. Because that stream is uncertain, “realistically support” does not mean preparing for every imaginable future. It means reasoning from the product, domain, architecture, and organization about which changes are credible enough to shape the design.
A plugin architecture is justified in a product that routinely adds third-party integrations; it is indefensible in a small internal CRUD tool. The same design move can be brilliant in one context and over-engineered in another, depending entirely on whether the modifications it anticipates are actually going to arrive.
Sufficient Context
Sufficiency is an information condition relative to the correctness bar below: enough facts to eliminate the modifier’s uncertainty about whether the change is correct. CMP does not lower this threshold, it only asks the same sufficient set to be cheaper to acquire, and avoid unrelated context.
Correct Modification
The bar is correctness: a change that is complete, preserves invariants, and produces the intended behavior.
Cheaper to Acquire
Cheapness has two axes: size and discoverability. A sufficient set is cheaper when it contains fewer facts, and the facts are more directly reachable.
A design that shrinks the set but leaves it hidden has not reduced cost; nor has a design that scatters the set across the codebase even if each fact is locally simple. Context size is theoretical; context acquisition cost is operational.
This is why “clean code” alone is not sufficient as a design goal. A codebase can be locally pristine—every function short, every name clear, every module focused—while still imposing enormous context cost because the relationships among those clean pieces are scattered, implicit, or unreliable to follow.
Taken together, these constraints turn CMP from a slogan into a comparative frame: scoped to realistic modifications, grounded in sufficiency, disciplined by correctness, and measured by context cost rather than by visible size alone.
With CMP in place, the familiar debates of software design—DRY versus simplicity, abstraction versus directness, eager structuring versus YAGNI—stop being clashes of taste and become comparable trade-offs in a single currency: the cost of acquiring sufficient context for safe modification.
The remaining question is how context cost actually grows. In the next chapters, we will see that it expands through two recurring patterns: Depth and Breadth. Most classical design principles can be reframed as moves that reduce, relocate, or index one or both of them.
Part II — The Shape of Context
Chapter 5
Depth: When Simple Calls Become Long Investigations
Depth is the context cost of acquiring the behavioral meaning of a focal artifact — and why boundaries only stop traversal when their contracts do the work.
A Short Call Site Can Hide a Long Investigation
Pick any reader on any ordinary task. A reviewer skimming a PR. A developer chasing a pricing bug. A new hire reading their way into the codebase. Someday they might land on a line like this:
const discount = calculateDiscount(order, customer)The line looks small. But before they can do anything with it — approve it, fix it, build on it — they have to answer the same question: how much do I need to read before I know what this line actually does?
The amount of context required to answer that can vary dramatically.
In one design, calculateDiscount is a direct function. Its name states the responsibility. Its parameter types expose the required inputs. Its return type makes the result clear. The discount rule lives in the function body, and its tests describe the important cases. A reader can open the function, read the contract and the nearby tests, and stop.
In another design, the same call enters a PricingService, delegates to a DiscountPolicy interface, resolves a concrete strategy through a runtime factory, reads a feature flag, consults user configuration, and finally computes the discount. The visible call site has not changed much. But the context behind it has expanded.
The call site is identical. The cost of understanding it is not. This pattern of hidden context is the first axis in CMP: depth.
Depth is the context cost of acquiring the behavioral meaning of a focal artifact.
It includes the artifact’s own code and the surrounding structure a reader must traverse before what it promises and what it requires are sufficiently understood.
Depth is not a symptom of design failure. It is an inherent cost of code comprehension. An artifact has depth because its behavior must be expressed in code: in its own body, and in the callees, callers, interfaces, configuration, schemas, and protocol definitions that surround it.
Some depth reflects how hard the problem actually is. A complex business rule may legitimately require more code and more context than a simple rule. CMP does not treat that cost as waste. It asks whether the required context is proportional to the behavior being expressed, and whether the surrounding structure prevents that cost from spreading farther than necessary.
Depth has a focal point. The focal artifact may be a function, class, module, interface, endpoint, service, schema, or framework extension point. Depth asks: if this artifact is placed in front of a reader, how much surrounding structure must be loaded before its behavior is clear?
The answer depends on two things together. The first is the code’s topology around the artifact — the calls, imports, and references that link its body to the surrounding code. The second is whether the boundaries along that topology carry contracts strong enough to let the reader stop. Topology describes which edges exist; boundaries decide which of those edges have to be crossed. Both are properties of the code as it stands, not of any particular modification task: once you’ve picked the artifact in question, its depth is fixed by the structure and contracts that already surround it.
A Boundary Stops the Reader Only If Its Contract Does the Work
If depth is inherent, design cannot eliminate it. What design can do is decide whether it stops locally.
Every layer of structure creates a possible stopping point. A function call may be opened. An interface may lead to its implementations. A service may lead to repositories, adapters, and policies. A factory may lead to runtime selection rules. A feature flag may lead to configuration. A framework annotation may lead to lifecycle behavior. A remote client may lead to another system’s protocol.
Each of these is a place where the reader could, in principle, stop walking. Whether they actually do depends on what the boundary offers.
A boundary acts as a stopping point when its contract carries enough of the behavior needed at that level — when the implementation does not have to be opened to recover it. A boundary that fails to do this is still a boundary, with a name and a location, but the reader has no reason to stop crossing it.
The relevant question at a boundary is therefore not whether the implementation is correct, but whether the observable behavior is sufficiently explained: what it promises, what it requires, what it returns, what it may fail to do, what side effects it performs, and which invariants it preserves. A boundary that captures these does not eliminate the implementation’s complexity; it makes that complexity unnecessary for ordinary reasoning.
Consider a payment boundary:
type ChargeRequest = {
amount: number
currency: string
cardToken: string
}
type ChargeResult = {
success: boolean
transactionId?: string
errorMessage?: string
}
interface PaymentGateway {
charge(request: ChargeRequest): Promise<ChargeResult>
}The type signature tells us that a charge request produces a charge result. But the signature alone may leave the behavior unresolved:
- Is the operation idempotent?
- What happens after a timeout?
- Can the payment be captured but reported as failed locally?
- Which failures are retryable?
- Can the result be pending?
- How are currency and precision represented?
- Which external side effects may already have occurred?
If these questions are not expressed by the boundary, the reader has to open the implementation to recover them. The interface exists, but it does not stop traversal. Each missing obligation becomes another step inward.
A contract that answers all seven questions
type Currency = "USD" | "EUR" | "JPY"
type MinorUnits = number & { readonly __brand: "MinorUnits" }
type Money = { currency: Currency; minorUnits: MinorUnits }
type IdempotencyKey = string & { readonly __brand: "IdempotencyKey" }
type ChargeId = string & { readonly __brand: "ChargeId" }
type CardToken = string & { readonly __brand: "CardToken" }
type ChargeRequest = {
idempotencyKey: IdempotencyKey
amount: Money
cardToken: CardToken
}
type PermanentFailure =
| { kind: "card_declined"; reasonCode: string }
| { kind: "invalid_request"; field: string }
| { kind: "insufficient_funds" }
type ChargeOutcome =
| { status: "succeeded"; chargeId: ChargeId; capturedAt: Date }
| { status: "failed"; reason: PermanentFailure }
| { status: "pending"; chargeId: ChargeId; pollAfter: Date }
| { status: "unknown"; idempotencyKey: IdempotencyKey }
type TransientError = { kind: "transient"; retryAfter?: Date }
interface PaymentGateway {
/**
* Idempotent by idempotencyKey: repeated calls with the same key
* return the same ChargeOutcome.
*
* Resolves with a definitive ChargeOutcome (including `unknown`).
* Rejects only with TransientError; the caller MAY retry with the same key.
*
* `unknown` means an external charge may exist. The caller MUST reconcile
* via getStatus before reporting a final outcome.
*
* No side effects other than the charge itself; notifications and ledger
* writes are driven by webhooks, not by this call.
*/
charge(request: ChargeRequest): Promise<ChargeOutcome>
/** Returns the current ChargeOutcome for a known idempotencyKey. */
getStatus(key: IdempotencyKey): Promise<ChargeOutcome>
}The example above answers its seven questions through several language mechanisms: discriminated unions distinguish pending, unknown, and failed; branded types make IdempotencyKey and Money impossible to mistake for ordinary strings or numbers; a separate error type carries retryability. And several obligations — that charge rejects only on transient errors, that unknown must be reconciled via getStatus, that no other side effects occur — live in the docstring, not in any type. Comments are weaker than types — they are not checked and they drift — but obligations like these cannot be carried any other way, so they remain a necessary part of the contract. How to combine these mechanisms is the task of later boundary principles. For now, the diagnostic is enough: when behavior is not explicit at the boundary, the reader keeps traversing.
Depth Runs in Both Directions
Depth is often imagined from the caller’s side: a reader starts at a call site and walks inward through the implementation until the behavior becomes clear. But structural comprehension has a second direction.
An implementer modifying the inside of an artifact must understand what the outside is allowed to depend on. If the boundary contract is incomplete, the implementer cannot safely reason locally. They must scan callers to discover which assumptions are in use.
A reliable boundary therefore stops traversal in both directions:
From outside to inside, callers should not need implementation details to use the artifact correctly.
From inside to outside, implementers should not need caller-specific assumptions to change the implementation safely.
Take a DiscountPolicy interface. If its contract clearly states whether discounts may be negative, whether multiple discounts are composable, whether customer segmentation is part of the policy, and whether the returned amount includes tax, then both sides can reason locally. Callers do not need to inspect every concrete policy. Policy implementations do not need to inspect every checkout, billing, analytics, or promotion-preview caller.
If the contract does not state these obligations, depth expands outward as well as inward. A caller must inspect implementations to understand behavior. An implementer must inspect callers to understand dependency expectations.
This is why boundary reliability is more than encapsulation. Encapsulation hides code. A reliable boundary hides context.
Indirection Redistributes Depth
It would be tempting to read the previous sections as an argument against indirection — every interface, factory, hook, or service is another traversal edge, another place the reader might fail to stop. But indirection is not the opposite of depth, and it is not equivalent to it either.
A program can have several layers of indirection and still be shallow if each layer carries a reliable contract. A program can have almost no explicit abstraction and still be deep if behavior depends on implicit state, hidden side effects, global conventions, or runtime magic. Indirection does not create or destroy depth; it redistributes it.
The clearest case is a long function. A single procedure that mixes validation, pricing, persistence, notification, and error handling holds all of its depth in one continuous local context. The reader cannot stop until they have walked the whole body. Extracting those regions into functions whose names and contracts match real sub-responsibilities adds calls but reduces what must be loaded at any one time: the top-level body becomes a sequence of meaningful steps, and the reader opens only the step whose behavior matters.
The same refactoring can fail. If extraction merely hides arbitrary lines behind vague names, it adds traversal without creating a useful stopping point — the reader still has to open each call to recover the behavior, and now has more places to look. Indirection reduces depth only when it compresses local complexity into a boundary the reader can trust.
The Failure Mode of Depth: Exhaustion
When indirection fails to compress, or when an implementation does more than its boundary admits, depth cannot be contained locally. The reader still understands eventually — but the path is long, fragmented, and cognitively expensive. They follow calls, inspect implementations, decode binding rules, reconstruct failure semantics, infer side effects, and compare scattered tests before the artifact’s behavior becomes clear.
For a human developer, this appears as attention drain: too many files open, too many assumptions in working memory, too much switching between local behavior and global structure.
For an AI coding agent, it appears in observable traces: larger retrieval sets, rapidly exhausted context windows, more tool calls, more irrelevant edits, and more test-driven correction loops. A senior developer may carry implicit project knowledge that lets them shortcut the traversal. An agent has no such shortcut; it must read the actual implementation to recover what the senior developer carries in memory. The deeper the artifact, the more implementation it has to load to make sense of it.
Depth Is Inherent; Boundaries Decide Where It Stops
Within CMP, depth names the local structural cost of understanding behavior around a focal artifact. It explains why a short call site can hide a large comprehension burden, why abstraction can either reduce or increase context cost, and why information hiding only works when a boundary carries a semantic contract.
Good design does not eliminate depth. Some depth is the price of expressing real behavior, and complex domains will legitimately carry more of it. What design can do is place boundaries that partition that depth into regions a reader can comprehend locally. How to design boundaries that do this — responsibility contracts, dependency inversion, interface segregation, substitutability, module depth, client-shaped abstractions — belongs to the later discussion of boundary principles.
Chapter 6
Breadth: The Things You Forgot to Change
Breadth is the cost of acquiring every artifact that must be considered together for a realistic change to be correct — and of knowing the modification closure is complete.
A Small Edit Can Reach More Places Than It Appears
In the previous article, we discussed depth: the structural cost of understanding a focal artifact. Depth describes the static structure of code. Breadth begins from a different experience.
Suppose a team changes a discount rule.
The visible change may start in one obvious place: a pricing function, a checkout component, or a policy object. The code at that location may be clear. The local boundary may be reliable. The function may have low depth.
Yet the change can still be wrong.
The checkout UI may show the new discount, but the billing job may still apply the old rule. The order service may validate one version, while the analytics pipeline classifies discounted orders using another. Documentation may still describe the old condition.
No single artifact is hard to understand. The problem is that the modification required several artifacts to be considered together, and one of them was missed.
This is breadth.
Breadth is the cost of acquiring every artifact that must be considered together for a realistic change to be correct.
It measures how hard it is to discover that complete set and to be sure that nothing has been missed.
Depth asks how hard one artifact is to understand. Breadth asks which artifacts must be brought into context together.
Modification Closure
Most engineers have felt these sets long before they had a name for them. While writing a feature, you find yourself editing several places — a schema column, a validator, a UI field, a background job — and notice that nothing in the code records the fact that these places belong together. Their relationship lives only in the decision you happen to be making right now. That is when an alarm fires. The next person to change this code — possibly you, a few weeks from now — will not have this decision in mind, and one of these places will be missed.
This sense has a name in CMP.
A modification closure is the set of artifacts that must be considered together because a realistic modification requires them to change, be checked, or remain consistent together.
The word “artifact” should be read broadly. A closure may include source files, tests, schemas, migrations, UI components, API definitions, background jobs, configuration, event consumers, fixtures, external protocol definitions, or documentation.
The closure is easiest to see while it is being created. Writing a feature or fixing a bug forces you to load the whole closure into your head at once — you are reaching into the schema, the validator, the UI field, the background job, and noticing how each piece has to match the change you are making. Nowhere else in the lifecycle of the code is the entire set so naturally present in one person’s working memory.
This makes writing the best moment to notice problems inside the closure: edits that look local but quietly imply edits elsewhere, places where a future modifier could plausibly land without ever discovering the rest. Experienced engineers even train this check into a sense of code-smell. While editing, part of their attention is running an automatic question — “if I were the next person changing only one of these places, would I find the others?” When the answer is no, we can feel that something is wrong.
This is what makes modification closure operational where earlier design principles stay abstract. “Single Responsibility” tells you a module should have one reason to change. “Things that change together belong together” tells you to co-locate co-changing code. The trouble with both principles is that their definitions hinge on a hypothetical future. “Reason to change” and “things that change together” describe modifications that have not happened. To apply either one, you have to imagine the future changes you think might arrive and ask whether the current code will hold up under them. That imagined future is open-ended: there is no signal that tells you when enough scenarios have been considered, and nothing in the code to verify your guess against.
Modification closure is defined as “considered together” too, but from a different angle. The code you are writing right now to complete one feature or fix one bug is, by definition, the closure — you can see it directly in what your hands are touching. The design question that remains is concrete: what trace will you leave behind so the next modifier, who will not have your decision in mind, can still find every member?
The most important property of a closure is completeness. Breadth is the cost not just of identifying closure members but of knowing the set is whole. A closure is only useful once every member has been found. A modification that touches most of its closure but misses one member is not “mostly correct”; it is incorrect, just incorrect in a place that has not surfaced yet.
The Failure Mode of Breadth: Omission
When a closure is incomplete, it fails in a particular way. The modifier never visits a place that belonged to it. The code that did get changed compiles, runs, and passes its local tests. The review looks clean. The patch seems complete. But somewhere in the codebase, an artifact that needed to move with the change has been left at the old behavior, and the gap will not surface until something downstream depends on it.
This is why omission is more dangerous than depth’s failure. Depth fails by exhaustion: the reader keeps following structure because they cannot find a trustworthy stopping point — too many jumps, too many abstractions, too many hidden behaviors. The work is slow, tiring, and context-heavy, but the cost is visible while it is happening, and anyone watching can see the reader struggling. Breadth fails the opposite way. The modifier feels nothing during the work, because nothing in the code surfaces the missing member; they believe the closure is complete simply because no path through it revealed otherwise. Depth hurts during reading; breadth hurts after forgetting.
When the missing member does surface, it is rarely at the original site of the change. It shows up as a stale report, a mismatched UI, a broken export, a billing inconsistency, an outdated migration assumption, or a downstream consumer that still sees the old behavior.
Breadth is therefore not only an effort cost; it is a confidence cost. The cost has two parts — how many artifacts belong to the closure, and how reliably the modifier can know the closure is complete — and the second part is usually the heavier one. A modifier does not just need relevant context; they need sufficient context. For breadth, sufficiency means being able to answer not one question but two:
What do I need to change?
and:
How do I know I have found everything that must change or be checked together?
Breadth Is the Cost of Knowing the Closure Is Complete
Within CMP, breadth names the task-level cost of context. Where depth measures how hard a single artifact is to understand, breadth measures which artifacts a single change has to bring into context together — and how confidently the modifier can tell when that set is whole.
The two costs are not symmetric. Depth is a property of the code being read: a given artifact has roughly the same depth regardless of what change is being made to it. Breadth is a property of the change being made: the same artifact can sit in very different closures depending on the modification, so asking about the breadth of a codebase is not a meaningful question — one can only ask about the breadth of a particular modification on it.
This gives them complementary jobs:
Depth is the structural cost of understanding a focal artifact.
Breadth is the task-level cost of acquiring the artifacts that must be considered together.
Breadth selects the artifacts a modification has to consider. Depth prices each one. A real modification pays both.
Software design matters because software must change. For depth, sufficient context means the modifier could understand each artifact they touched. For breadth, it means they reached every artifact that had to move with the change — and could trust that nothing was missing. Breadth, in the end, is the cost of knowing the closure is complete.
Later articles will show how design can reduce or manage breadth — through locality, indexing, architecture, tests, and language mechanisms. The next article brings depth and breadth together and looks at how real design moves transform context between them.
Chapter 7
Context Transformation: How Design Changes the Shape of Context
Breadth selects artifacts; depth prices each one. Design moves transform context by reducing, relocating, indexing, or making it checkable.
The previous two articles introduced the two primary shapes of context cost. Depth is the structural cost of understanding a focal artifact. Breadth is the cost of acquiring the modification closure of a realistic change — the set of artifacts that must move together for the change to be correct.
This article brings the two together and uses them to ask a new question: when a design move makes future modification easier, what is it actually doing?
Breadth Selects the Artifacts, Depth Prices Each One
A single picture summarizes the two-shape view.
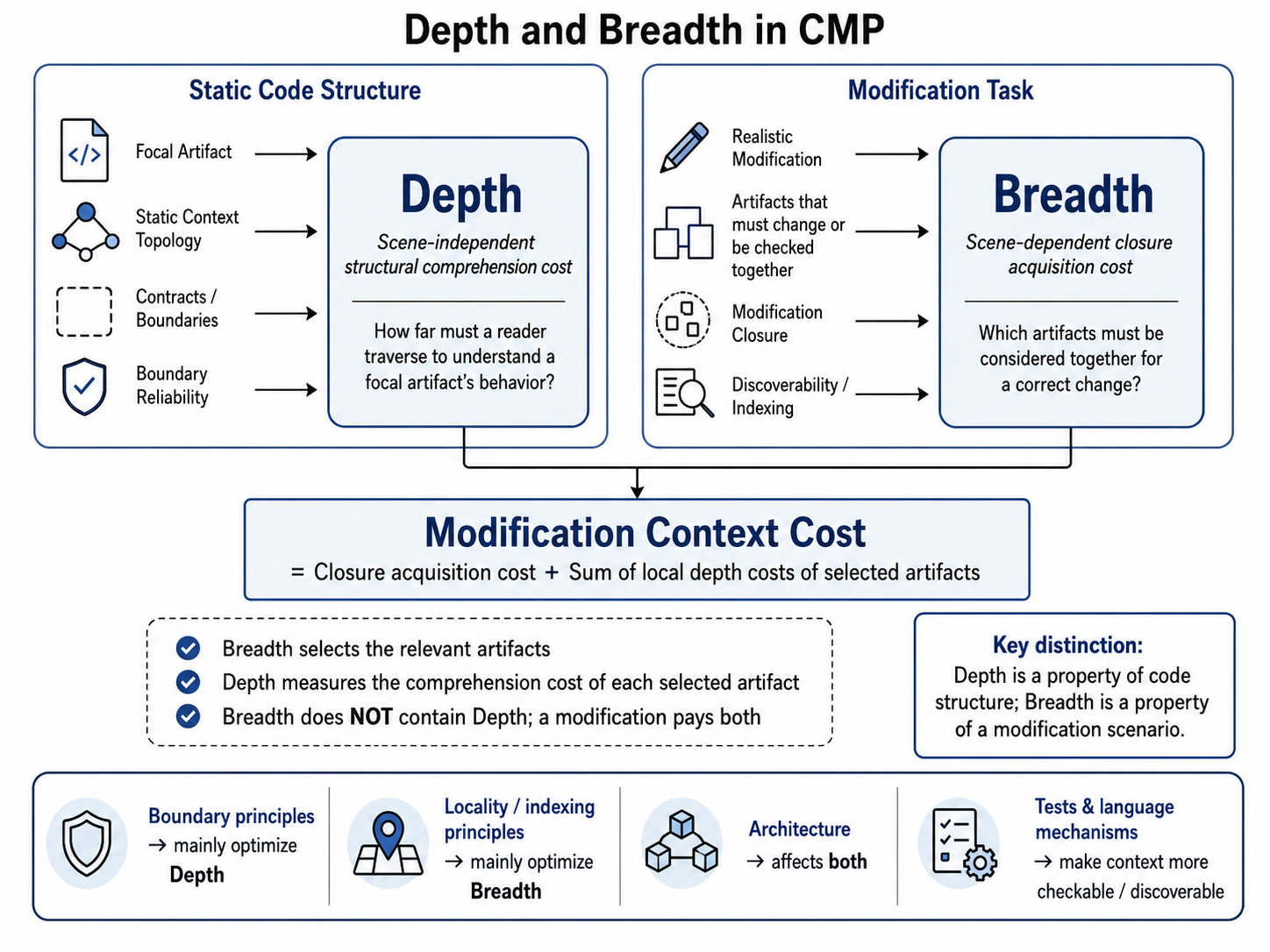
Figure 1. Depth belongs to static code structure. Breadth belongs to a modification scenario. A real modification pays both: the cost of acquiring the relevant closure, plus the local depth costs of the selected artifacts. (Image generated with GPT Image 2.)
Any real modification answers two different questions. Which artifacts belong to this change? That is breadth. For each of those artifacts, how much local context does the modifier need to edit or verify it safely? That is depth. In practice the two are interleaved — reading one artifact often surfaces another that belongs to the closure, and each new closure member opens its own local-context question — but the costs stay conceptually distinct. Breadth selects the artifacts; depth prices each one.
This separation has practical consequences. A codebase can have locally understandable artifacts but still be dangerous to modify, because change-together relationships are scattered. It can also have well-localized modifications whose selected artifacts are individually hard to understand. These are different problems, and design must address each one.
Design Reshapes Context: Reduce, Relocate, Index, Check
Design rarely makes context disappear. More often it transforms context — the same information takes a different shape, lives in a different place, or surfaces through a different path. A decision that was once duplicated across several places may be collapsed into one named abstraction. A complex implementation detail may be moved behind a boundary. A scattered set of related artifacts may remain distributed, but become discoverable through an explicit path. A previously implicit assumption may be recorded in a test, type, schema, or protocol and become checkable. In each case, the system may not contain less total information. What changes is the shape of context acquisition.
This is CMP applied to a single design move. CMP asks whether one design is better than another by checking whether the sufficient context for correct modification is cheaper to acquire. Asked of an individual move rather than a whole design, the same principle gives a single test.
A design move is valuable when it transforms required context into a cheaper acquisition shape.
“Cheaper” here carries the same operational meaning CMP gives it: it depends on size and discoverability. Concretely, a design move can make context cheaper in a few different ways. Sometimes it means fewer artifacts. Sometimes it means better stopping points. Sometimes it means more visible relationships among distributed artifacts. Sometimes it means turning a fragile assumption into executable feedback.
Those four “sometimes” shapes correspond to four basic transformations a design move can perform. Reduce shrinks the set a modifier must acquire, by collapsing a duplicated decision into one owned place. Relocate moves detail behind a boundary, so the reader pays a smaller surface cost at a stopping point instead of a larger internal cost. Index keeps a closure distributed but makes its members reachable together, turning open-ended search into bounded acquisition. Check moves an assumption into a test, type, schema, or validator, so a missing piece surfaces as failure rather than silent defect.
These are not mutually exclusive: a single design move can reduce one closure, introduce a boundary, create an index, and make some assumptions checkable. The point is not to label every technique into exactly one bucket, but to see that design changes the acquisition path, not merely the visual shape of the code.
Every Transformation Trades One Cost for Another
Every transformation has a price, which is why design debates are often difficult. Most design moves improve one form of context cost while worsening another. An abstraction may reduce breadth by collapsing several duplicated decisions into one named place, but it also adds a new concept and a new boundary that readers must understand. A layered architecture may reduce open-ended search by making decision placement predictable, but it also adds traversal through layers. A registry may keep a distributed closure discoverable, but it introduces a lookup mechanism that future modifiers must learn.
These trade-offs are why vague labels rarely settle design disagreements. The same structure may be called “cleanly factored” by one engineer and “over-abstracted” by another. The difference is often not that they disagree about the code they can see, but that they are pricing different context costs. One person is focused on the breadth avoided by the abstraction. The other is focused on the depth introduced by the new boundary.
CMP reframes the disagreement in a more useful form: for the realistic modifications this system must support, what context cost does this move add, and what context cost does it remove, relocate, index, or check? That question does not make judgment automatic, but it makes the hidden ledger visible. A design move stops being “good” or “bad” in the abstract and becomes a trade against an expected modification stream.
One asymmetry is worth naming. Depth and breadth do not deserve equal weight when their costs are compared, because they fail differently — depth fails visibly during the work, breadth fails silently after the work is shipped. A slow change can still be correct; an incomplete change cannot. For that reason it is often reasonable to pay some visible depth to control real breadth: a boundary, registry, type, or test may add surface cost, but the cost is justified when it prevents a closure member from being missed. The bias is not absolute — paying depth for imaginary breadth is over-engineering — but when the closure is real, breadth tends to deserve the heavier vote.
Revisiting the Discount Rule: A Trade in Practice
The breadth article opened with a discount rule scattered across the checkout UI, the order service, the billing job, and the analytics pipeline. Treated as a breadth problem, the danger was clear: a future modifier might update three of the four places and ship a quiet inconsistency. The transformation vocabulary lets us look at the same scenario from the design side.
A common design move is to introduce a named abstraction, such as DiscountPolicy, and make the relevant parts of the system depend on it. This is a reduce move: it collapses a scattered decision into one owned concept, so the future modifier no longer has to rediscover four independent representations of the same rule. It is also an index move: with the named type as an anchor, every place that depends on the rule is one find-references away — the closure is no longer something the modifier has to rediscover by grep and tribal knowledge.
But the move is not free. The system now has a new concept, a new boundary, and perhaps a new traversal step. Readers must understand what DiscountPolicy means and what behavior its contract guarantees. In other words, the design has traded some breadth for some depth.
That trade is good if the new boundary is reliable and the old closure was real. It is bad if the abstraction is vague, shallow, or premature. The duplication-abstraction debate becomes clearer when phrased this way: the issue is not whether duplication or abstraction is universally better, but whether the added depth is smaller and more reliable than the breadth it removes.
Design Principles Are Context Operators
With depth, breadth, and context transformation in hand, classical design principles can be read in a new way. They are not freestanding rules of taste; they are context operators. Boundary-oriented principles primarily act on depth by creating stopping points. Locality-oriented principles primarily act on breadth by making modification closures smaller or more reachable. Architecture routes context acquisition by making decision placement predictable. Tests and language mechanisms make parts of context checkable, so missed assumptions surface as feedback rather than silent defects.
Each of these families deserves its own treatment, which is the job of Part III. This article’s job was only to set the shared frame; the next chapters take up the major operators one at a time — boundaries, locality, architecture, tests, and language mechanisms.
Part III — Design as Context Engineering
Chapter 8
Boundary Principles: Hiding Context, Not Code
Boundary principles are context operators on depth — semantic contracts that let modifiers stop without loading implementation details behind them.
Design Principles as Context Operators
The previous essays established the basic vocabulary of CMP: software development is primarily an activity of modification; the cost of a modification is not the amount of code changed, but the context required to make the change correctly; and that context can take different shapes — Depth, Breadth, implicit assumptions, omission risk.
From this essay onward, CMP becomes a lens for rereading familiar design principles.
Classic principles are not arbitrary conventions — they have lasted because they solve real problems in how software evolves. Information hiding, dependency inversion, interface segregation, substitutability, openness to extension — these are all valuable ideas. But they are often taught as if they were unconditional rules. Hide information. Depend on abstractions. Keep interfaces small. Open for extension, closed for modification.
Real systems are less clean. Every abstraction has a cost. Every boundary charges rent. Every principle assumes some future pattern of change, and that assumption might be wrong.
In CMP, a design principle is not a style preference. It is a context operator: a way of organizing context for cheaper future modifications. Different principles operate on different shapes of context.
Boundary principles primarily operate on Depth. They try to stop a modifier from digging further into implementation details. Locality principles primarily operate on Breadth. They merge duplicate logic together, or create an index over related modification points, so scattered decisions can be found, compared, and changed together. This essay focuses on the first family: boundary principles.
A Boundary Hides Context, Not Code
It is tempting to think of a boundary as a structural object: a module, a class, an interface, a facade, a service, a package, a process.
Those are places where a boundary may appear. They are not the boundary itself.
A module can simply move complexity into another directory. An interface can mirror every method of a provider. A facade can add one more hop before the reader reaches the real implementation. These structures may hide code, but they do not necessarily reduce the context required for modification.
A real boundary is not created by separation. It is created when the modifier no longer needs to keep digging into details.
For a boundary to hold, three things must be true:
- It abstracts a responsibility.
- It expresses that responsibility as a contract.
- The modifier can reason from that contract without crossing into the implementation behind it.
A nominal boundary hides code. A semantic boundary hides context.
The distinction matters. A nominal boundary can make the architecture diagram look cleaner while still forcing the modifier to load implementation details, historical assumptions, and provider-specific behavior. A semantic boundary changes the shape of context acquisition. The modifier reaches the boundary and already has enough context to perform the modification reliably.
A Good Name Is the Shortest Contract
A responsibility also needs a good name.
A contract is not only a method signature or a type definition. The name of the responsibility is part of the contract. In fact, it is often the shortest, most frequently referenced, and most widely propagated part of the contract.
A good name compresses a set of assumptions into a reusable token. When a modifier sees the name, they can activate existing domain knowledge and engineering experience, then continue reasoning from the concept the name represents.
This is similar to prompting an LLM. A precise term can be more effective than a long explanation because it activates a whole region of learned structure. Humans work similarly. A name like Cache immediately brings to mind source of truth, TTL, stale data, misses, invalidation, and fallback. Transaction brings commit, rollback, isolation, and failure boundaries. In the business domain, Cart, Order, and Invoice each carry a different set of rules and constraints.
A name is a context package.
But that also means a rich name comes with obligations.
You cannot call something a Cache and require callers to treat it as the source of truth. You cannot call a flow a Transaction if it has no rollback semantics. You cannot call an object an Invoice if it can be freely edited without audit implications. A good name reduces explanation because it borrows shared understanding. If the implementation violates that understanding, the name stops reducing context and starts generating confusion.
When a responsibility is hard to name, that is often not a writing problem. It is a design signal. It may mean we have not found a stable responsibility yet. We may have merely bundled a set of implementation details that happened to be adjacent at the time. Such a boundary usually needs more comments, more documentation, more examples, more tests, and more oral tradition to explain what it means. The context that the name failed to carry returns in another form.
An interface named OrderHandler can be declared with typed method signatures and documentation. But the name does not let the caller stop at the boundary. Handle how? Validate? Fulfill? Cancel? Which operations are idempotent? Which provider semantics have been folded into this contract?
Designing a Good Boundary
So far we have described what a boundary does. The harder question is how to design a good one.
The L and I parts of the SOLID principles answer the first half of this question: what does a good boundary look like?
- Liskov Substitution Principle asks: can different implementations satisfy this contract without forcing the caller to load each implementation’s special behavior?
- Interface Segregation Principle asks: does this caller receive only the context required for its modification class, rather than a large surface of unrelated methods, states, and failure modes?
When a boundary fails these checks, the boundary has not become semantic: either provider details still leak through the contract, or the contract exposes surface the caller never needed.
How do we design boundaries that pass these checks?
The answer is in the D of SOLID: Dependency Inversion.
DIP is often explained as “depend on abstractions, not concrete implementations,” or as a way to make implementations easier to swap. These explanations are not wrong, but they are shallow. The important question is not whether a concrete class has been replaced by an interface. The important question is:
Who wrote the interface?
There is an old saying in product thinking: the customer is always right.
It does not mean customers are factually correct about everything. It means the value of a product must be defined from the side that pays the cost. A supplier should not put something on the shelf merely because they can produce it. The shelf should be organized around what the customer is willing to pay for.
Software boundaries work the same way.
In code, a provider-shaped abstraction is like a supplier-driven product. It takes whatever the provider can offer and wraps it in an interface. Because it does not know how it will be used, it is tempting to include everything “just in case.”
This predictably breaks both LSP and ISP. A PaymentProvider interface modeled after Stripe might expose a charge() method with Stripe-specific parameters and error codes. Swap in PayPal, and the caller learns the contract never truly abstracted anything: PayPal’s pre-authorization model does not fit, and the error codes do not map. The caller must know which provider sits behind the interface. That is LSP failing. The same interface might expose thirty methods — charge, refund, dispute, subscription, invoice, webhook management — even though the client only needs charge and refund. The client still has to navigate the full surface. That is ISP failing.
A client-shaped abstraction asks a different question: what does the client actually need to do its job? Which concepts is the client willing to pay a context cost for? Which failure modes must be visible to the client’s reasoning? Which provider differences should remain behind the boundary? These questions will lead to names the client can reason with. Not StripeChargeRequest, but PaymentIntent. Not StripeChargeResult, but PaymentOutcome. Not a provider’s raw error code set, but the modification semantics the client actually cares about: declined, retryable, needs 3DS.
This is the real value of Dependency Inversion: it gives authorship of the contract back to the client. More than that, it gives naming authority back to the client. Once the contract is authored by the client, LSP and ISP become less like external rules and more like consequences.
LSP holds because the contract describes the semantics the client needs. Any implementation that satisfies those semantics can be substituted without forcing the client to load subtype-specific behavior.
ISP holds because the contract only contains capabilities the client is willing to pay a context cost for. Provider capabilities that the client does not need to understand never appear on the interface.
OCP is also a consequence, not a starting point. When the contract’s axis matches the real axis of modification, new providers, new implementation strategies, and new internal changes can happen behind the boundary without forcing existing clients to rewrite their reasoning. “Open for extension, closed for modification” is not achieved by adding an abstraction in advance. It emerges when the boundary, DIP, LSP, and ISP are all aligned.
Boundaries Are Not Only Interfaces
The discussion so far used SOLID, interfaces, and subtypes because they are familiar boundary carriers in software design. But boundary principles are not OOP principles.
From CMP’s perspective, anything that limits the scope of context acquisition can be a boundary. An event payload can be a boundary: consumers depend on the event semantics without needing to know which internal state transitions the publisher went through. An HTTP API is obviously a boundary: a public contract. A state machine can be a boundary: it compresses a workflow into finite states and legal transitions, so the modifier can focus on a single state and its outgoing transitions, rather than untangling how the pieces might interact across the entire system.
Functional programming offers many boundary carriers as well. Option / Maybe puts absence into the type, so a modifier does not need to search the implementation for where null might appear. Either / Result turns failure paths into explicit contracts, so callers reason in terms of success and failure rather than tracing where exceptions might be thrown. Algebraic data types and pattern matching compress a set of possible states into a closed set of cases, making the required handling visible at the boundary.
Other boundaries look even less like “code boundaries”: SQL, Terraform, Kubernetes YAML, permission rules, validation rules, contract tests. They compress data access, infrastructure changes, deployment behavior, authorization decisions, input constraints, and cross-service agreements into languages or executable checks.
Their common feature is not form. Their common feature is context control.
When Boundaries Backfire
A boundary is a context transformation. That means it is not free.
Every boundary taxes the future. It adds a name, a contract, a conceptual surface, and a coordination relationship that must be maintained. The question is not whether boundaries are good. The question is whether the tax buys a real reduction in required context.
Boundaries commonly fail in five ways.
The first failure mode is that the assumed modification stream never arrives.
Many abstractions are built around a future story: we may switch payment providers, support multiple storage backends, add more execution engines. So the system grows adapters, interfaces, configuration layers, and names in advance. But if those changes never happen, the boundary remains pure cost. Every modifier must understand the abstraction, then discover there is only one implementation behind it. The boundary did not reduce Depth. It routed everyone through a detour.
The second failure mode is that change arrives along a different axis.
Suppose a payment system is designed around provider replacement. But the real changes are BNPL, revenue splitting, subscriptions, pre-authorization, regional compliance, or fraud workflows. The variation was not provider replacement. The variation was payment semantics. The boundary has the wrong shape. New modifications must bypass it, pierce it, or dismantle it. This is wrong-shape depth: the problem is not too little abstraction, but abstraction compressed along the wrong axis.
The third failure mode is context leakage.
A payment interface that still requires callers to understand Stripe error codes, PayPal state machines, or bank-channel timeout behavior has not formed a semantic boundary. It has renamed provider details without containing them. The caller must understand PaymentOutcome and the provider-specific behavior hidden beneath it. The implementer must satisfy the contract and still accommodate caller-specific assumptions. Neither side’s context has been cut cleanly. The boundary becomes carrying depth.
The fourth failure mode is misleading naming.
A good name is a context package, but the package must match the contents. Calling an authoritative data source a Cache, a non-rollbackable flow a Transaction, or a freely editable object an Invoice causes modifiers to reason from the wrong shared understanding. The most dangerous boundary is not one with no contract. It is one whose contract looks trustworthy while violating the community’s expectations at a critical point.
The fifth failure mode is hiding information that should have remained visible.
Not every detail should be hidden. Some failure modes, performance constraints, consistency assumptions, security boundaries, and audit requirements belong to the caller’s required context. If a boundary hides these facts in the name of cleanliness, local code may become simpler while its decisions become less reliable. The surface complexity goes down, but omission risk goes up.
Closing
One sentence captures boundary principles:
A good boundary lets local code do the right thing without needing a big-picture view.
It does not prescribe interfaces, modules, services, schemas, protocols, or types. It prescribes responsibility contracts to exclude implementation details, collaborator construction, provider-specific behavior, and caller-specific assumptions from the required context of future modifications.
The next group of principles shifts from Depth to Breadth. DRY, cohesion, and SRP are less about stopping a modifier from digging into details, and more about connecting related modification points: how repeated judgments are merged, how scattered context becomes discoverable, and how a set of related changes gets an index.
Chapter 9
Locality Principles: Designing Against Omission
Locality is not about putting similar code together. It is about making modification closure reachable from every legitimate entry point — for humans and agents alike.
The agent did the obvious work
An AI coding agent is asked to add Apple Pay as a new payment method.
The task looks small. The codebase already has a PaymentMethod type. Checkout already renders a list of available methods. The payment processor already dispatches to different providers. The agent finds the obvious entry points, adds "apple_pay" to the union, updates the checkout form, wires the new method into the processor, and adds a happy-path test. The test suite passes. The patch looks clean, local, and reasonable.
The agent even does what a careful agent should do. Before finishing, it asks a reviewer whether anything else needs to handle Apple Pay.
The reviewer thinks for a moment and remembers the admin order detail page. The agent adds a display label there too. Now the patch looks even more complete. It compiles. Tests are green. A human has looked at it. It seems ready to merge.
But the change is still incomplete.
A few days later, the omissions start showing up. Refunds for Apple Pay orders go through the wrong fallback path because the refund policy does not classify Apple Pay as a wallet payment. Settlement reports group it under other because the reporting map has no entry for the new method. Fraud scoring does not apply the wallet-payment risk rules. The i18n table has no display name. The test factory never generates Apple Pay, so some paths were never exercised. The analytics event schema still rejects the new value as unknown.
None of these failures require another service, another repository, or a complicated organizational boundary. They can all happen inside a single codebase. Every missing place is related to PaymentMethod, but the relationship is not necessarily recorded by a single explicit structure. The artifacts share a design decision: the system supports a new payment method.
Every local edit the agent made may have been correct. It knew how to update a union, adjust UI, add a test, and wire a processor. The failure was that starting from the natural entry point, PaymentMethod, the agent did not reliably acquire the complete modification closure.
Asking a human did not solve the problem either. The reviewer was not a closure oracle. The reviewer could only add what came to mind: recently touched modules, obvious names, familiar ownership areas. The missing mappings, policies, factories, reports, and schemas were still hidden because the system had no path that exposed them.
“I cannot think of anything else” is not proof that the closure is complete.
This is becoming a characteristic failure mode of agentic coding. The agent has enough context to produce a locally correct patch, but not enough context to make the whole modification correct. As models become better, this failure becomes more important, not less. Code generation gets cheaper; missing the context that should have been changed with the code becomes more expensive.
Locality principles are about this failure. They are not primarily about physical proximity, elegant class names, or whether everything sits in one file. They ask whether, when a real change begins from any valid entry point, the system lets a human or an agent find every artifact that must be considered together.
From breadth to locality
In the previous article on breadth, we named the set of artifacts that must be considered together for a change: the modification closure. It may include codes, tests, UI, configuration, documentation, reports, deployment steps, or anything else that must change, be checked, or remain consistent for the task to be correct.
Breadth is the cost of acquiring that set. It does not ask whether one file is hard to understand. It asks which artifacts must enter context together for this modification to be safe. When a required member of the closure never enters context, the change fails in a particular way: the code that was edited may be correct, but some necessary place was never visited.
That failure mode is omission.
Omission is dangerous because it often does not feel like failure while the work is happening. The agent edits what it can find. Tests pass. Review looks reasonable. Human developers experience the same thing. The modification can feel smooth because nothing in the visible path is especially complex. The real problem is that the system never exposed the other artifacts that belonged to the same closure.
Experienced engineers recognize this as a design smell. While making a change, they notice several places moving together and realize that the codebase does not record why they belong together. The alarm is not “this code is already broken.” The alarm is “the next modifier may enter from one of these places and never find the rest.”
Locality is the design property that answers that alarm.
Locality is the design property that makes the complete modification closure reachable from the place where a legitimate change naturally begins.
The phrase “naturally begins” matters. A change might start from a failing test, a type definition, an API field, a UI option, a configuration key, an event payload, a business rule, or a user-reported bug. Good locality does not require every relevant artifact to sit beside that entry point. It requires explicit paths from the entry point to the rest of the closure.
For humans, locality reduces the cognitive cost of change. It reduces the need to search the whole system or rely on memory. It helps a developer know what to inspect, what can be ignored, and when the closure is likely complete.
For agents, locality is also a reliability property. A strong model can reason well over context it has acquired. It cannot reason over an artifact that never entered context. Without locality, the agent can confidently produce a patch that is locally coherent and globally incomplete.
Agent reliability is therefore not only a property of the model. It is also a property of the codebase and the engineering system around it. Model capability determines how well the agent uses acquired context. Locality determines whether the agent can reliably acquire enough context in the first place.
Breadth names the cost of acquiring the closure. Locality is how design makes that acquisition reliable.
Re-reading DRY, SRP, and cohesion
Classic locality principles have survived because they point at real design pressures. DRY says not to duplicate knowledge. SRP says a module should have one reason to change. Cohesion says related things should stay together. These statements are useful, but their key terms are slippery. What counts as the same knowledge? What counts as one reason to change? What does related mean?
Modification closure gives these intuitions a more concrete object.
This matters because modification closure is not just another vague design noun. It is the set that the task itself constitutes in the modifier’s working memory. When you implement a feature — say, adding Apple Pay — by the time the work is done you have added a value to the PaymentMethod union, edited the checkout form, registered a handler in the processor, extended the refund policy map, added an entry to the settlement report grouping, updated the analytics schema, added a display name to the i18n table, removed an obsolete fallback branch, and adjusted the test factory so it can generate the new method. Every one of these files was opened, read, modified, added to, or deleted from in the course of completing the task. By the end, all of them sit together in your working memory as a single working unit — not as separate recollections that arrived one at a time. For the person doing this task, they are one piece of knowledge, one reason to change, related to one another by virtue of belonging to the same modification. The set is not invented by abstract classification, nor recovered by remembering; it is constituted by the task itself. These are the artifacts that must be considered together for this modification to be correct.
That makes modification closure more operational than “knowledge,” “responsibility,” or “relatedness.” It asks: for this concrete change, what would be wrong if we forgot it?
DRY: one decision, one (or indexed) representation
DRY is often reduced to “do not write similar code twice,” but similarity and sameness of decision are different things. A User domain entity and a UserRecord persistence model may share fields yet encode different decisions (business invariants vs. storage layout); PaymentMethod, refund policy, display names, analytics values, and test factories look nothing alike yet all encode one decision: which payment methods this system supports.
From a locality perspective, DRY is a rule about duplicated representations of the same decision: they should either collapse into one owned place or be reachable from one another. The real DRY failure is an unindexed decision with multiple representations.
SRP: a reason to change is a closure family
SRP says “a module should have one reason to change,” but reasons are hard to count. The typical SRP failure is conceptual: responsibility or one thing gets defined too broadly. A whole business process — “order processing,” “user onboarding,” “checkout” — sounds like one thing in conversation, but it bundles pricing, inventory, payment, fulfillment, notification, analytics, and more, each with its own modification closure and its own reason to change.
Once these unrelated closures live on the same modification surface, every change leaks across them. A pricing tweak drags you through fulfillment code; a notification change forces you to reason about payment state; a fix to one closure ships unintended edits in another. The scope of a small change keeps inflating because closures that should have stayed separate are now entangled.
Locality reframes the question: do the closures inside this module form a coherent family, or have unrelated closures been collapsed onto the same modification surface because they were misnamed as one responsibility?
A module should not force unrelated modification closures to share the same modification surface.
Cohesion: co-change reachability
Cohesion is usually stated as “related things belong together,” but related is too broad. Locality gives it a narrower meaning: a module is cohesive when its artifacts serve closures that are commonly acquired together and are easy to reach from one another. Cohesion is co-change reachability — less a separate rule than an outcome of good locality.
DRY, SRP, and cohesion are three views of the same reachability judgment. The old principles were not wrong; locality turns their intuition into a question humans and agents can act on: what is the closure of this change, and is it reachable from where the change begins?
How locality is implemented
Locality is not only a property of the code. The mechanisms that implement it fall into three layers, distinguished by how they enforce the closure:
- Code — anything expressed as source, tests, or CI/CD artifacts. These provide feedback through execution: a missing closure member can fail a build, fail a type-check, fail a test, or fail a pipeline check.
- Architecture — conventions about where things live and how parts of the system connect: directory layouts, module boundaries, dependency direction, service boundaries, API and event schemas, contracts. Conventions don’t fail a build, but they sharply narrow the search space.
- Documentation — purely textual hints: comments, READMEs, ADRs, runbooks, checklists. No enforcement, only reachability for whoever is reading.
All three matter, as long as they turn what would otherwise live only in someone’s memory into something the next modifier can follow.
Code-level indexes
Code-level indexes encode closure relationships in artifacts that can be executed or tested, so a missing member produces feedback before the change ships. The strongest forms make the closure a compile-time obligation. A type like Record<PaymentMethod, RefundPolicy> says “a map that must have a RefundPolicy for every value of PaymentMethod” — if you add apple_pay to the union without giving it a policy, the code stops compiling. Exhaustive switch statements, generated code, and similar constructs work the same way: adding a new variant without updating its dependent mappings becomes a build error.
Tests carry the same idea to runtime. A normal happy-path test only proves that the path the agent edited works. A completeness test asserts the closure itself — for every member of an enumerated set (every payment method, every order status, every supported locale), the required mapping, handler, or policy exists. For payment methods, useful locality tests might assert:
- every payment method has a display name
- every payment method has a refund policy
- every payment method has an analytics value
- every payment method has a risk category
- the test factory can generate every supported method
Each of these turns an omission into a visible failure long before it can become an incident in production.
The same mechanisms extend past application code. Migrations, feature flag configurations, infrastructure definitions, dashboards, alert rules, runbooks, and release checklists all ship as files in the repository and participate in the same enforcement: a missing migration entry fails the build, an alert without an owner fails a lint, a rollout step that depends on an absent dashboard fails a check. Wherever the closure relationship is written down as something a tool can read, the tool can refuse an incomplete change.
Design patterns also belong here. Their value is not elegance but the way they make a common closure traversable:
- Visitor and exhaustive matching serve variant closures. Adding a new AST node, payment state, or order status may affect parsing, evaluation, serialization, rendering, validation, snapshot generation, and autocomplete. Exhaustive matching turns the closure into a list of required handlers.
- Registry and plugin registry serve membership closures. Adding a payment method, export format, notification channel, or integration provider should not require guessing every
if. Membership is declared in one artifact, with one set of required fields. - Strategy serves policy-family closures. Adding a refund policy, pricing rule, or risk scoring method should reveal the interface, existing implementations, shared tests, and registration point — Strategy makes a family of policies enumerable.
Patterns, completeness tests, and CI-as-code help when they turn “where else should I look?” into a path the tooling can follow. When they add layers without improving closure reachability, they are ceremony.
Architecture-level indexes
Architecture-level indexes are conventions about where things live and how parts of the system connect: directory layouts, module boundaries, dependency direction, service boundaries, API schemas, event schemas, and contracts. They cannot fail a build on their own, but they sharply narrow where a modifier needs to look. If payment capabilities always live under payments/capabilities, analytics values are generated from one schema, and external events declare producer, consumer, and compatibility rules under events/contracts, a modifier does not need to search the entire codebase.
Across system boundaries, locality and boundaries become two views of the same property. A working boundary hides context: a modifier on one side does not need to acquire what lives on the other side, only the contract between them. When the boundary fails — an undocumented consumer, a missing compatibility rule, a contract that has drifted from reality — the hidden context rejoins the closure, except the modifier has no path to reach it from where the change begins. A boundary failure is therefore also a locality failure: the closure now includes downstream consumers, versions, and behaviors that are invisible to the side making the change.
Documentation indexes
Documentation indexes carry no enforcement — they are purely textual hints meant to be read. Comments, READMEs, ADRs, AGENTS.md, skills, runbooks, release checklists, and deprecation policies, as long as they live where humans and agents can find them.
The lightest index may be a comment:
// When adding a PaymentMethod, also update:
// - refundPolicyByPaymentMethod
// - settlementReportGroups
// - analytics allowed values
// - i18n display names
// - paymentMethodFactory test coverage
type PaymentMethod = "card" | "paypal" | "bank_transfer"This comment does not enforce anything. But it changes reachability. A future human or agent entering through PaymentMethod no longer sees only a union; they see a map of the closure they may need to acquire. For an agent reading the file, the comment functions as an index it can follow next.
Because of this, comments and documents in an agentic codebase deserve the same care as code. Plain words are no longer commentary alongside the code — agents read them as part of the same input and act on them the same way. Documentation is no longer a weaker artifact than code, only a different kind of one.
Closure retrospectives are the only chance
Locality problems are nearly invisible by construction. A closure that was not reachable from the entry point leaves no trace at the place the change began — the diff records what was edited, not what should have been edited together, nor how the missing pieces were eventually found.
But the end of a development task is a point at which the modification closure exists as a directly observable object. To do the work, the agent had to acquire it. By the time it finishes, its context contains an unusually complete record: which files it read, which it changed, which context turned out useful, which was noise, which necessary artifact was discovered late, which path depended on search, guessing, or human prompting. The diff discards almost all of this. For a human, that knowledge fades within hours. For an agent, it disappears the moment the context window resets. If the closure is not captured here, it will not be observable anywhere else.
This makes the closure retrospective not a useful add-on but the workflow’s main locality mechanism. Code-level indexes, architecture, and documentation can only encode closures someone has already noticed; the retrospective is what surfaces the closures that no existing index has yet caught. Without it, locality problems can still be recovered later — through an incident, a careful re-read, or a future modifier entering from a different path — but reconstructing the closure that way takes far more effort and rarely reaches the same confidence as capturing it while it is still intact.
An agentic workflow should therefore end with a closure retrospective. The agent should ask:
- What was the goal of this task?
- What context is loaded for this task?
- Which changed artifacts served the same feature or design decision?
- Should those artifacts be co-located?
- If not, what index connects them?
- Could the next human or agent find the same closure from any reasonable entry point?
- What index would make the next change safer?
This is not a normal task summary. A normal summary says what was done. A closure retrospective says what context had to be acquired and whether the system recorded the relationships correctly.
The output should be design feedback. If several files always move together, maybe they should be co-located. If they cannot be co-located, maybe they need a comment, registry, test, contract, or runbook. When the agent is adding settlementReportGroups for Apple Pay is the cheapest moment to drop a line in the PaymentMethod registry noting that the report system uses it.
A practical pattern for this feedback loop is post-change design reflection: turning the context an agent just paid during a task into focused, actionable locality and design signals before that context disappears.
Locality as reliability
Locality is ultimately about reliability.
It prevents a human or an agent from confidently missing what had to change together. As model capabilities improve, more failures will move from “the agent could not write the code” to “the agent did not do it right.”
Agent reliability is therefore not only a model property. It is also a property of the codebase and engineering system. A system with poor locality constantly produces closure-incomplete context: enough to generate a plausible local patch, not enough to guarantee a correct change. A system with good locality exposes the paths that make sufficient context reachable, confidently.
This reframes DRY, SRP, cohesion, design patterns, contracts, tests, and comments under one goal: make the modification closure reachable from the natural entry point of change.
Locality is reliability — the design property that decides whether the next change finds everything it must move with it, or only what it happens to see.
Chapter 10
Architecture as Context Routing
Architecture is a routing map for context acquisition. This chapter explains how architectural styles match modification patterns, why placement rules enable reuse, and how post-change reflection maintains routing trust.
Software architecture is often described through its visible structures: layers, modules, services, components, dependency directions, interfaces, adapters, and boundaries. These descriptions are useful, but they easily make architecture look like a static arrangement of boxes.
From the perspective of the CMP, architecture is not primarily about what the system looks like. It is about where a modifier should go when the system needs to change.
When a developer or an AI coding agent starts a modification, the architectural question is not abstract. It is immediate:
- Where should this decision live?
- Which path should I follow to acquire the required context?
- Which parts of the system should not need to be searched?
- Which boundary can I trust enough to stop reading?
- Which owner, module, layer, context, or extension point is responsible for this change?
This is the practical value of architecture.
Architecture is a context-routing system.
It earns its cost when it makes decision placement predictable. It tells future modifiers how to acquire sufficient context without turning every modification into a full-codebase search.
A good architecture does not eliminate context. It routes context. It tells us where to start, which paths are legitimate, where related decisions should be found, and where the search is allowed to stop.
A bad architecture may still have all the visible forms of architecture: layers, folders, modules, interfaces, services, and diagrams. But if those structures no longer predict where decisions actually live, they no longer route context. The map remains visible, but it stops working.
Architecture Exists to Reduce Unbounded Search
CMP starts from a simple claim: software design exists because software must be modified. Correct modification requires sufficient context. A design is better when the sufficient context required for realistic modifications is cheaper to acquire.
At the local level, boundaries reduce traversal depth when their contracts let modifiers stop reading. Locality reduces breadth when related change surfaces are co-located or indexed. Architecture applies the same logic at system scale.
Architecture reduces the cost of unbounded search.
Without architecture, a modifier often has to ask open-ended questions:
- Is this rule in the controller, the service, the model, the database trigger, or the frontend?
- Is this validation duplicated in the API, the UI, the import job, and the reporting pipeline?
- Does a reusable implementation of this already exist somewhere, or should I write my own?
- Is this concept shared across the whole company, or does it mean something different in each domain?
- Is this behavior owned by the core system, a plugin, a workflow, or an integration?
These are not merely comprehension problems. They are modification risks. If the modifier cannot reliably know where a decision belongs, they cannot know when their context acquisition is complete.
Architecture answers these questions by imposing placement rules.
A placement rule says: this kind of decision belongs here, not everywhere. Domain rules belong in the domain owner. Infrastructure details belong behind adapters. Cross-context communication belongs behind published contracts. Feature-specific behavior belongs inside the feature slice. Plugin-specific behavior belongs behind an extension point. Team-owned business capabilities belong inside the owning module or service.
A placement rule routes in two directions. Forward, it tells a modifier where a new decision belongs, so the patch lands where future modifiers will expect it. Backward, it tells a modifier where an existing capability would already live, so they can look for a reusable implementation before building another one. The same rule that answers “where should this go?” also answers “does this already exist?”
Reuse depends on that backward direction. When a capability has a predictable home, checking whether it already exists is a bounded lookup. When it does not, the question “has someone already built this?” becomes another unbounded search, and a modifier working under context cost will rationally stop searching and write a fresh copy. Duplication is the backward-search failure of a missing placement rule, not a lapse of discipline.
When placement rules hold, the modifier can route their search. They can start in a bounded region. They can ignore unrelated regions. They can stop at trustworthy boundaries. The system becomes cheaper to modify not because there is less code, but because the required context is easier to find.
When placement rules do not hold, the modifier cannot trust the architecture. They first look where the architecture says the decision should be, then search everywhere else anyway. At that point, the architecture has become pure carrying depth: the system still pays the cost of its structure, but loses the search-reduction benefit.
Architecture Selection Is Modification-Pattern Matching
Architectural styles are often taught as competing ideals. Layered Architecture, Clean Architecture, Hexagonal Architecture, DDD’s Bounded Context and Context Map, Vertical Slice Architecture, Microservices, Modular Monoliths, Plugin Architecture, and Entity-Component-System each come with their own vocabulary and structure.
CMP reframes them differently.
Every architectural style embeds a prediction about future modifications.
An architectural style says: future changes will usually have this shape, therefore context should be routed along this topology.
When the prediction is right, the architecture reduces context cost. When the prediction is wrong, the architecture becomes indirection, ceremony, or fragmentation.
This means architecture should not be selected by taste, seniority, fashion, or diagram elegance. It should be selected by matching routing topology to the dominant modification patterns of the system.
The question is not: Which architecture is cleanest?
The question is: What kinds of modifications must this system realistically support, and which architecture makes the required context cheapest to acquire for those modifications?
For example:
- A product team repeatedly adds small fields to admin screens: add a column, expose it in an API, validate it, store it, show it in a table, and update a test. The change always cuts vertically through the stack.
- A pricing team frequently changes discount, eligibility, tax, or billing rules, while the database, web framework, and UI change for different reasons. Policy and mechanism evolve separately.
- A marketplace uses the word
Productdifferently in catalog, inventory, search, fulfillment, and accounting. The same term appears everywhere, but each area changes its meaning under different business pressure. - A growing organization discovers that most changes are delayed not by code complexity, but by finding which team owns the rule, which service owns the data, and which contract other teams are allowed to depend on.
- A platform keeps adding payment providers, import formats, notification channels, AI tools, or editor extensions. Each new capability follows the same extension path, and the core should not be reopened every time.
- A game or simulation keeps adding behaviors that cut across object types: movable things, damageable things, inventory holders, temporary status effects, AI-visible objects. The changes do not follow a clean inheritance tree.
- A reporting or analytics feature repeatedly changes read shapes, filters, projections, and dashboards, while core transaction rules remain stable. Most work is representation change, not domain-policy change.
- A compliance-heavy workflow fails if one validator, approval step, audit record, or notification is missed. The problem is not just making the change; it is reliably acquiring the whole closure.
These situations are modification patterns. They describe the recurring shape of future work: where changes begin, which artifacts tend to change together, which decisions need stable owners, and which omissions would make the modification incorrect.
With that in view, architectural styles become easier to compare. They are not universal solutions. They are routing topologies optimized for different modification streams.
Layered, Clean, and Hexagonal Architecture: Routing Policy Away from Mechanism
Layered, Clean, and Hexagonal architectures make a strong prediction: policy and mechanism change under different pressures.
Put more simply, policy is about what the system should do; mechanism is about how the system gets it done. Policy includes business rules, use cases, domain behavior, invariants, and application-specific intent. Mechanism includes the tools and delivery details that execute those decisions: databases, frameworks, user interfaces, transport protocols, queues, file systems, payment providers, and infrastructure APIs.
The routing promise is clear:
- policy changes should route inward;
- mechanism changes should route outward;
- domain behavior should not require loading framework, database, UI, or transport context;
- infrastructure changes should not rewrite domain policy.
This is why these architectures place ports, adapters, interfaces, repositories, controllers, gateways, and use cases around a policy core. The value is not the shape of the diagram. The value is that a modifier can ask: am I changing policy or mechanism?
If the answer is policy, the search should move toward the domain or use-case layer. If the answer is mechanism, the search should move toward adapters and infrastructure. The routing topology works when this distinction is stable.
For example, suppose a pricing rule changes. In a well-routed system, the modifier should not need to inspect HTTP controllers, ORM mapping details, framework annotations, database drivers, or frontend state management. Those may be involved in execution, but they should not own the pricing decision. The architecture lets the modifier stop before acquiring irrelevant mechanism context.
But the same structure can be a bad trade in a simple CRUD system. If most modifications are field-level vertical slices — add a field to the form, validate it, save it, show it in a table — then strict policy/mechanism separation may force every ordinary change through multiple layers, DTOs, ports, mappers, repositories, and adapters. The architecture predicts that policy and mechanism will evolve separately, but the actual modification pattern constantly crosses them together. In that case, the architecture does not route context. It fragments the modification closure.
Clean or Hexagonal Architecture is justified when policy complexity is high enough, and mechanism volatility is independent enough, that separating their acquisition paths reduces more context cost than the boundaries add.
It is over-architecture when the ordinary modification stream is mostly simple vertical CRUD and the added boundaries do not let modifiers stop earlier.
DDD Bounded Context: Routing Semantic Context
Domain-Driven Design is broader than architecture. It includes a full discipline of domain modeling, ubiquitous language, aggregates, entities, value objects, repositories, domain services, and more. In this article, the architectural part we care about is DDD’s strategic design, especially Bounded Context and Context Map.
That part of DDD makes a specific architectural prediction: semantic meaning does not stay globally uniform, and each domain needs room to evolve independently.
In a large enough business, the same word may mean different things in different places. Order in sales, fulfillment, shipping, and accounting may carry different rules, lifecycle states, and invariants. More importantly, those meanings do not change at the same time or for the same reasons. Catalog may refine how products are classified, inventory may change how stock is reserved, billing may change how product charges are recognized, and recommendation may change how products are ranked. A single shared model would force all of these changes through one semantic surface.
A bounded context routes semantic context.
Its promise is not merely modularity. Its promise is that a modifier working inside one domain should not have to load the entire enterprise model. They should be able to rely on the language, model, invariants, and rules of the local context. When they cross into another context, they should do so through an explicit translation boundary: an API, event, published language, anti-corruption layer, or contract.
The routing promise is:
- semantic changes stay inside the owning context;
- cross-context understanding is routed through explicit contracts;
- no modifier needs to load a universal model for every local domain change;
- no external caller should depend on the internal model of another context.
This style is valuable only when the system is large enough for those semantic surfaces to need independent evolution. If the business is small, or if one team can still maintain a single shared model without constant negotiation, bounded contexts may add translation cost before they create real routing value.
One wording trap matters here: DDD also uses the word context. In this section, a bounded context is a domain-specific semantic boundary. It is not the same thing as CMP’s broader notion of context as the information required for modification. This also demonstrates a typical semantic problem in DDD: the word context has different meanings in the DDD bounded context and in the CMP bounded context.
DDD’s bounded-context architecture is justified when semantic modification closures are naturally local and would otherwise be polluted by a global model.
It is over-architecture when the system does not have enough semantic fracture to justify the translation cost.
Vertical Slice Architecture: Routing by Feature-Level Change Surfaces
Vertical Slice Architecture makes almost the opposite prediction from strict layered design.
It predicts that most modifications arrive as feature-level or use-case-level slices. A change does not usually affect only the controller layer, or only the service layer, or only the persistence layer. It affects a complete path: request handling, validation, command or query logic, persistence interaction, response shape, and tests.
The routing promise is:
- a feature change should be found inside one feature slice;
- use-case-specific behavior should not be scattered across horizontal layers;
- the modifier should not need to jump through the whole technical stack to understand one product behavior;
- the closure of a feature-level modification should be local to the slice.
This style is effective in systems where the product is naturally a collection of independent workflows, screens, commands, or user operations. Many internal business applications, SaaS back-office systems, admin panels, workflow tools, approval systems, content-management systems, and reporting portals have this shape. Most changes are not deep changes to a shared domain model. Each change has a recognizable product entry point, a limited rule surface, and a modification closure that mostly belongs to that workflow. The architecture routes context to that slice rather than forcing the modifier through global controller, service, repository, and persistence layers.
Vertical slices become a poor fit when the apparent feature is only the surface of a deeper shared policy. A coupon change, for example, may involve pricing, eligibility, tax, billing, and promotion rules. In such a system, the real owner is not the coupon screen or request handler, but the pricing or promotion policy. Putting that logic into isolated slices would duplicate the decision and make future rule changes harder to acquire.
The advantage is locality. A slice can contain the request model, handler, validation, query, command, tests, and small feature-specific decisions together. For many application systems, this matches the real shape of change better than horizontal layering.
Vertical Slice Architecture is justified when feature-level modification closures dominate and shared domain policy remains small, explicit, or separately owned. It becomes under-architecture when shared domain decisions are copied across slices and no reliable index connects them.
This contrast is important. Clean Architecture and Vertical Slice Architecture are not simply rivals. They optimize for different modification patterns. Clean Architecture routes by policy versus mechanism. Vertical Slice Architecture routes by use case. The better choice depends on which context acquisition path the system will need more often.
Modular Monolith and Microservices: Routing Ownership Context
This section is close to DDD’s bounded-context architecture, but it operates one level lower.
A bounded context is a semantic boundary: it says where a model, language, rule set, and business meaning are allowed to evolve independently. A module or service boundary is an implementation and ownership boundary: it says which code, data, runtime, contract, and team own that area of change.
In a well-aligned system, the implementation boundary often mirrors the semantic boundary. A domain that owns its own language and rules becomes a module in a Modular Monolith, or a service in a Microservice architecture. This is why the two ideas often feel similar. One describes the boundary in domain meaning; the other enforces the boundary in software and organization.
But the mapping is not automatically one-to-one. A small system may contain several semantic contexts inside one deployable monolith. A large system may split one broad domain into several services for scaling, team ownership, operational isolation, or release independence. The important question is not whether each bounded context becomes exactly one service. The question is whether the implementation boundaries preserve the modification routes implied by the domain boundaries.
Modular Monoliths and Microservices both route context through ownership boundaries. Their difference is boundary strength.
A Modular Monolith keeps deployment unified but enforces internal module boundaries. A Microservice architecture strengthens those boundaries through separate deployment, runtime isolation, network contracts, databases, and often team ownership.
The routing promise is:
- a business capability has an owner;
- most modifications should complete inside the owning module or service;
- cross-boundary changes should go through contracts, APIs, events, or explicit coordination;
- modifiers should not need to load unrelated business capabilities to change a local one.
This style becomes valuable when ownership cost dominates modification cost.
In a small system built by one team, a single codebase with clear modules may be enough. The cost of crossing process boundaries, network calls, deployment pipelines, distributed tracing, eventual consistency, and contract versioning may exceed the benefit.
In a larger organization, however, context cost often becomes socio-technical. The modifier does not merely need to read code. They need to know who owns a rule, which team can approve a change, which service may publish an event, which contract is stable, which database is private, and which assumptions are allowed across boundaries.
Microservices are justified when hard technical boundaries reduce organizational context cost more than they add distributed-systems cost. They force modification paths to respect team and capability ownership.
But microservices are a bad trade when the actual modification pattern cuts across many services for ordinary changes. Then every feature becomes distributed modification. The modifier must acquire context across network boundaries, data ownership boundaries, deployment boundaries, monitoring systems, and team responsibilities. The architecture multiplies context cost instead of reducing it.
A Modular Monolith is often the intermediate routing topology. It can make ownership visible without forcing every boundary to become a distributed-systems boundary.
The key CMP judgment is not monolith versus microservices. It is whether implementation boundaries preserve the system’s real modification routes. When they do, module and service boundaries reduce context cost. When they do not, they turn local changes into distributed search.
Plugin Architecture: Routing Repeated Variation Through Extension Points
Plugin Architecture makes a very specific prediction: future modifications will repeatedly arrive along stable extension axes.
Examples include editor plugins, payment providers, import/export formats, authentication strategies, notification channels, workflow actions, AI tools, language integrations, and custom business rules.
The routing promise is:
- new capability should be added through an extension point;
- the core should not need to be modified for every new variant;
- plugin metadata, manifests, registries, or contracts should index all participants;
- the modifier should know exactly where a new extension belongs.
This is a strong context-routing pattern. The architecture turns repeated breadth into indexed extension.
Without a plugin architecture, every new provider or capability may require editing core dispatch logic, configuration, UI options, permission checks, documentation, tests, and deployment logic. The modification closure is broad.
With a plugin architecture, the modifier follows a predictable route: implement the contract, declare metadata, register the plugin, add tests, and let the core discover it through the extension mechanism. The closure may still include several artifacts, but the architecture makes them reachable.
The failure mode is wrong-shape extensibility.
If the future variation axis is not yet known, designing a plugin system too early can freeze the wrong boundary. The extension point exposes the wrong contract, requires the wrong lifecycle, hides the wrong assumptions, or supports the wrong type of variation. Future modifiers then fight the plugin architecture instead of using it.
Plugin Architecture is justified when the variation axis is stable and repeated.
Entity-Component-System: Routing State and Behavior Through Composition
Entity-Component-System, or ECS, is often discussed in game development and simulation systems, sometimes in relation to performance. But from a CMP perspective, its architectural value is not only performance. It is a routing topology for highly compositional change.
Traditional object-oriented hierarchies predict that future modification follows taxonomy. Behavior is found by walking class hierarchies: Entity, Character, Player, Enemy, Vehicle, Projectile, and so on.
ECS makes a different prediction: future behavior changes will cut across taxonomies.
A game feature may affect all movable things, all damageable things, all entities with health, all entities affected by gravity, all objects with inventory, all temporary status effects, or all objects visible to AI perception. These modification patterns do not map cleanly to inheritance trees.
ECS routes state to components and behavior to systems.
The routing promise is:
- data lives in components;
- behavior lives in systems;
- feature modifications follow component-system composition rather than class hierarchy traversal;
- adding a capability means composing entities with the relevant components and systems.
This reduces context cost when the domain is combinatorial. The modifier does not ask, “Which subclass owns this behavior?” They ask, “Which component represents this state, and which system processes it?”
The architecture is justified when future changes are hard to predict along a single taxonomy but repeatedly combine orthogonal capabilities.
It is a bad fit when the domain is small, stable, and naturally hierarchical. In that case, ECS can add conceptual surface without enough routing benefit.
Again, the decision is modification-pattern matching. ECS works when composition is the real shape of change.
When Architecture Works
The architectural styles above differ in structure, but they can be judged by the same question: does this architecture route context along the system’s real modification patterns?
If most changes separate policy from mechanism, Clean or Hexagonal Architecture can route domain decisions away from framework and infrastructure details. If the hard problem is semantic independence across business domains, DDD’s bounded-context architecture can route each domain’s language and model into its own semantic boundary. If most work arrives as independent workflows or operational screens, Vertical Slice Architecture can route context by use case. If modification cost is dominated by ownership, team coordination, or business capability boundaries, Modular Monoliths or Microservices can route context through modules or services. If the system repeatedly grows along stable extension axes, Plugin Architecture can route new capabilities through extension points. If behavior is highly compositional and cuts across object taxonomies, ECS can route state and behavior through components and systems.
These choices are not mutually exclusive at every scale. A system may use bounded contexts at the domain level, a modular monolith as its implementation boundary, vertical slices inside a module, and plugin points for repeated extension. The important judgment is whether each boundary answers a real modification pattern, rather than merely adding another architectural shape.
A working architecture therefore makes context bounded, discoverable, and trustworthy.
Bounded means context paths have borders. The modifier knows where to start and where to stop. A pricing rule belongs in the pricing domain. A payment provider belongs behind the payment integration port. A plugin belongs behind an extension point. A shipping concept belongs inside the shipping domain.
Discoverable means related surfaces are reachable, in two directions. Forward, the modifier can find the rest of the closure — the artifacts that must change together — through names, types, tests, registries, schemas, contracts, ownership records, dependency rules, or architecture tests. Backward, the modifier can find what already exists before building something new, learning whether a rule, capability, or helper has already been implemented and where. The relationship among artifacts is recorded in the system, not merely remembered by a senior engineer.
Trustworthy means the paths can be relied upon. This is the most important property. If modifiers do not trust the architecture, they will route around it. They will search everywhere, read through every layer, distrust every boundary, and duplicate decisions for local convenience.
Architecture truly works only when it allows modifiers to stop searching.
This stopping power is the real payoff. A boundary that cannot stop traversal is only indirection. A layer that does not predict decision placement is only a folder. A service boundary that does not align with ownership is only distributed overhead. A plugin contract that does not match the real variation axis is only ceremony.
The test of architecture is not whether the diagram looks clean. The test is whether future modifiers can acquire sufficient context through the routes the architecture claims to provide.
Reusable Capabilities Need a Home
The discoverable property carries a sharp consequence that is easy to miss. Reuse is only possible when existing capabilities can be found, and finding them depends on placement rules and ownership.
Most of the styles above route domain decisions, and domain decisions come with natural owners: pricing logic lives in the pricing domain, shipping logic in shipping. Cross-cutting capabilities — a date formatter, a retry wrapper, a parsing helper, a validation primitive — have no domain to anchor them. The fix is ordinary: a tools or utility module with a clear owner usually keeps them findable. The point is that this placement rule and its ownership are themselves part of the architecture. When the architecture defines where such capabilities live and who owns them, a modifier checks one predictable place before writing their own. When it leaves that undefined, there is no first place to check, and duplication becomes the structural default rather than a discipline failure. This predates AI: human-maintained codebases reinvent the same helper for exactly the same reason.
This becomes a concrete requirement on architecture. A reusable capability must have a predictable placement rule and a clear owner, even when it belongs to no domain — a shared kernel, a utility module with a named owner, a registry, or an index that keeps it reachable. Discoverability is the precondition for reuse, and placement and ownership are the precondition for discoverability. An architecture can route every domain decision flawlessly and still accumulate duplication if it leaves its shared capabilities homeless, because the cheapest correct-looking action for each modifier is to build their own.
An agent makes this requirement easy to verify. Whenever a modification searches for an existing capability, fails to find an authoritative one, and creates a fresh implementation, the trace records a homeless responsibility: a capability with no discoverable home. Each occurrence marks a placement rule the architecture has yet to define.
Architectural Corrosion as Routing Failure
Architectural decay is often described as impurity: a domain rule in a controller, an infrastructure concern in the domain, a direct dependency across a boundary, a shared helper that should not be shared, a shortcut around a port, a weakened architecture test.
CMP gives a sharper explanation.
Architectural corrosion is routing failure.
The immediate shortcut often looks harmless. The current diff is smaller. The task finishes faster. No visible disaster occurs. But the placement rule has been weakened.
A domain rule placed in a controller teaches future modifiers that rules might live in controllers. A persistence assumption inside a domain model teaches them that mechanism context may leak inward. A cross-context shortcut through a shared table teaches them that semantic boundaries cannot be trusted. A query projection that duplicates a command invariant teaches them that read models may secretly own correctness.
Each violation does two things.
First, it creates local hidden breadth. The decision now lives in a place where future modifiers may not look.
Second, it weakens the global routing topology. Future modifiers can no longer trust that similar decisions live where the architecture says they should live.
This is why small architectural violations have disproportionate cost. The damage is not only the local line of code. The damage is loss of routing trust.
The effect is similar to trust-based businesses. A bank, an insurer, an exchange, or a certification authority does not survive merely by completing individual transactions. Its value depends on the belief that its promises can be relied upon. A small breach of trust is not evaluated only by the size of that breach; it raises the larger question of whether the whole institution can still be trusted. Architecture has the same property. Once a modifier finds one domain rule hidden in a controller, the question is no longer just about that rule. It becomes: where else might the architecture be lying?
Once trust is lost, modifiers pay twice. They still pay the carrying depth of the architecture: layers, services, interfaces, contracts, adapters, tests, deployment units. But they no longer get the benefit of bounded search. They must search both inside and outside the official route.
Every Modification Traverses the Architecture
Architecture is not used only during design reviews. It is used during every modification.
A modifier begins from an entry point: a failing test, a bug report, a feature request, an API endpoint, a domain rule, a schema field, a UI behavior, a log message, or an event payload.
Then they acquire context. They follow names, types, tests, call chains, dependency edges, schemas, ownership notes, documentation, registries, and runtime behavior. They encounter boundaries and decide whether to trust them. They cross some boundaries and stop at others. They identify the owner of the decision. Finally, they place the patch somewhere.
That path is not incidental. It is an empirical sample of the architecture’s routing behavior.
A modification reveals whether the architecture actually works:
- Did the natural entry point lead to the right owner?
- Did the boundary contract let the modifier stop?
- Did the required closure become discoverable?
- Did the modifier need global search?
- Did the final patch land where future modifiers will expect it?
- Did the change strengthen or weaken the placement rule?
Every modification either reinforces the architecture or corrupts it.
This is especially visible with AI coding agents. Agents do not have the same tacit team memory as senior engineers. They rely more heavily on explicit artifacts: file names, tests, types, documentation, dependency structure, and tool feedback. When architecture routes context clearly, agents can follow it. When routing is implicit or corrupted, agents fall back to broad search and local patching.
AI does not remove the need for architecture. It makes the quality of architecture more observable.
Post-Change Reflection as Routing Maintenance
The best time to evaluate architecture is immediately after a modification.
At that point, the modifier has fresh evidence. They know which files had to be opened, which boundaries failed to stop traversal, which concepts were hard to locate, which relationships were discoverable, which decisions had unclear ownership, and where the final patch landed.
This makes post-change reflection a practical architecture maintenance tool.
The reflection does not need to redesign the system. It only needs to ask whether the modification respected the architecture’s routing promises.
A locality check asks whether the modification closure remained reachable through the architecture’s intended routes:
- From any meaningful entry point in the change surface, could the rest of the closure be reached by following the system’s normal routing paths: module ownership, domain boundary, feature slice, registry, schema, test structure, or dependency rule?
- Did the modifier have to abandon the architecture and rely on global search, memory, or guesswork?
- Did the change reveal a missing architecture index, such as an ownership note, contract test, registry entry, schema link, architectural rule, or documentation path?
A boundary check asks whether the touched boundaries still functioned as routing stops:
- Which architectural boundaries did this task touch: layer boundary, domain boundary, module boundary, service boundary, adapter boundary, extension point, or public interface?
- Did the boundary contract provide enough context for the modifier to stop, or did they have to cross it to recover hidden details?
- Did caller-specific assumptions reshape a shared boundary and make future routing less predictable?
An ownership check asks:
- Who owns the decision that changed?
- Did the patch land in that owner’s context?
- Did a helper, abstraction, or shared module gain unclear responsibility?
- Did the modification rebuild a capability because no owner or home made the original discoverable?
- Did a local convenience move a decision away from its rightful home?
A routing integrity check asks:
- Can future modifiers still trust the original route?
- Did the change introduce a shortcut dependency?
- Did it weaken an architecture test, contract test, or dependency rule?
- Did it duplicate a decision across a boundary without indexing the closure?
This kind of reflection is small, but it targets the real mechanism of architectural decay. Architecture usually does not collapse through one grand mistake. It decays through many locally reasonable shortcuts. Post-change reflection catches those shortcuts while they are still small.
This reflection is useful for human developers, but it fits AI coding agents especially well. Human memory is selective and lossy; after a task is done, a developer may remember that a change felt messy but not exactly which searches failed or which boundary first became suspicious. An agent often still has much of its context acquisition history in the context window: inspected files, search attempts, traversal paths, test feedback, corrected assumptions, and crossed boundaries. That makes post-change reflection unusually precise. It can turn the agent’s working trace into architectural feedback: which routes worked, which boundaries failed, which ownership was unclear, and which missing index should be added.
Architecture Is Maintained at Modification Scale
Architecture is often treated as something designed up front, documented in diagrams, and reviewed occasionally. But in a living system, architecture is maintained or corrupted through ordinary modifications.
Every change deposits a decision somewhere. Every change either preserves or weakens a placement rule. Every change either makes future context acquisition cheaper or more expensive.
This is why architecture cannot be judged only by its static structure. A system may look architecturally clean and still be expensive to modify if its routing rules are not trusted. Another system may look less formal but remain highly modifiable because its decision placement is predictable, its ownership is clear, and its modification closures are easy to acquire.
CMP gives architecture a concrete criterion:
An architecture is good when its routing topology matches the system’s realistic modification patterns, and when its placement rules remain trustworthy enough to make sufficient context cheaper to acquire.
That criterion explains both the value and the cost of architectural styles.
Clean and Hexagonal architectures work when policy and mechanism changes need separate routes. DDD’s bounded-context architecture works when semantic changes are local to different domains. Vertical Slice Architecture works when feature-level changes dominate. Modular Monoliths and Microservices work when ownership boundaries dominate modification cost. Plugin Architecture works when variation repeatedly arrives along stable extension points. ECS works when composition is the real shape of change.
Each style is a prediction about future modification.
When the prediction is right, architecture routes context.
When the prediction is wrong, architecture becomes bad investment.
Architecture is not the diagram of a system. Architecture is context routing.
Chapter 11
Testing: Testability as Context Cost
Testability is the cost of acquiring the context needed to verify behavior. This chapter connects testing to CMP through verification context — entry, state, dependency, effect, and observation — and explains why TDD applies testability pressure early.
Engineers have long observed that hard-to-test code is often hard to maintain. This is usually treated as a practical testing problem: the code has too many dependencies, too much hidden state, or too many side effects. Those observations are correct, but they are symptoms of a deeper structure.
Testing a behavior requires context.
To write a meaningful test, a developer must know how to trigger the behavior, what state must exist, which dependencies influence the result, which side effects must be controlled, and what observable outcome proves the behavior is correct. When that context is small, explicit, and easy to control, the behavior is easy to test. When that context is large, hidden, or unstable, the behavior is hard to test.
This gives testability a direct CMP interpretation:
Testability is the cost of acquiring the context needed to verify behavior.
This is the main connection between testing and the Context Minimization Principle. Testing itself is a safety net for modification, but testability reveals whether the design has shaped behavior into a form whose verification context is cheap to acquire. This also explains why engineers have long treated testability as a design signal: a design that is easy to test is often easy to modify for the same reason — the relevant behavior can be reached, controlled, and observed through a bounded context.
Testing Requires Verification Context
Testing is sometimes described as simply checking whether code works. But meaningful testing requires more than executing code. It requires enough context to verify behavior.
That context has several recurring parts.
Entry context is the cost of reaching the behavior. Can the behavior be triggered through a clear function, service, API, or component boundary, or must the whole application be started before the behavior appears?
State context is the cost of preparing the situation in which the behavior runs. Can the required state be constructed locally, or does it depend on hidden global state, old database records, background jobs, or environment configuration?
Dependency context is the cost of controlling collaborators. Can dependencies be provided explicitly, replaced, or isolated, or does the behavior reach directly into infrastructure, clocks, networks, file systems, queues, or external services?
Effect context is the cost of isolating side effects. Does the behavior produce a focused result, or does it scatter consequences across logs, caches, events, database writes, background work, and remote calls?
Observation context is the cost of knowing whether the behavior was correct. Is there a stable output, state transition, event, or API response to assert, or is the only visible evidence an internal call sequence?
These are not testing details. They are design facts exposed by testing. A testable design makes these contexts cheap to acquire. An untestable design makes the test writer gather too much surrounding context before even reaching the behavior under test.
Testability as a Design Signal
The design signal appears most clearly in local testability: the ability to verify a unit, function, component, or service behavior at a local boundary.
A local behavior should usually have a local verification path. A small rule should be reachable without starting the whole application. A service behavior should be testable without unrelated setup. A component should expose an outcome that can be asserted without inspecting its private steps.
This gives local testability a simple standard:
A design is more locally testable when local behavior can be verified locally with enough confidence.
A clear entry point, constructible state, explicit dependencies, limited side effects, and observable results all lower the context cost of local testing. They also indicate that the behavior has been shaped into a boundary that is easier to understand and modify.
Poor local testability also explains many bad tests. When meaningful behavior is expensive to trigger, control, or observe, coverage pressure pushes developers toward cheap substitutes: asserting private helper calls, mocking long collaborator chains, freezing large snapshots, or testing incidental branches. These tests raise coverage numbers, but they do not create a trustworthy safety net. They are symptoms of high verification context cost.
This is why testability is one of the clearest everyday signals of CMP. Code that is easy to test is not automatically well designed, but persistent difficulty in testing ordinary application logic often means the design has made verification context larger than the behavior itself requires. The same excess context usually makes future modification harder as well.
TDD as Early Testability Pressure
TDD is often presented as a testing technique: write a failing test, make it pass, then refactor. Its deeper design effect is that it exposes verification context cost before implementation convenience takes over.
When tests are written after implementation, the implementation is already present. There are private helpers, branching structures, data flows, collaborators, and incidental details. Tests often follow that shape. They may confirm how the current implementation works rather than what behavior should remain stable.
TDD reverses the order. Before implementation exists, the developer must first ask:
- What behavior should be triggered?
- What state is needed?
- Which dependency must be controlled?
- What result should be observable?
- What failure would prove the behavior is wrong?
These are questions about verification context. If the answer is hard, the design pressure appears early. The developer needs a better entry point, simpler setup, more explicit dependencies, fewer hidden side effects, or a clearer observable result. TDD makes those needs visible before the implementation hardens around a less testable shape.
That is why TDD often improves design. Not because tests written first have magical power, but because the code must be designed from the outside of the behavior inward. The implementation must serve a testable contract instead of forcing tests to adapt to an accidental implementation structure.
For AI coding agents, this pressure is especially useful. An agent can quickly produce a plausible patch and then generate tests that merely follow the code it just wrote. A test-first workflow changes the order: before changing implementation, the agent must state what behavior should be verified and what observable result will prove it. This does not make the agent reliable by itself, but it reduces one common failure mode of agent-written tests: tests that validate the implementation rather than the behavior.
In CMP terms, TDD is not a new design principle. It is an early pressure toward lower verification context cost.
Testing as a Side View of CMP
Engineers already use testability as a practical signal of design quality. CMP explains why that signal is reliable: to test behavior, one must acquire the context needed to trigger, control, and observe it. When that cost is low, behavior tends to have clear boundaries, explicit dependencies, local state, stable contracts, and observable effects. These are exactly the design qualities that make modification easier.
So the lesson is simple:
Testability is not merely about tests. It is an observable form of context cost.
To test behavior, you must acquire the context needed to trigger, control, and observe it. When that context is expensive, tests become brittle, mock-heavy, shallow, or skipped. When that context is cheap, the same behavior is usually easier to understand and modify.
That is the CMP reading of testing. Testing provides the safety net, testability reveals the context cost of building that safety net, and TDD applies that pressure early enough to influence design.
Chapter 12
Programming Languages Are Boundary Infrastructure
A programming language is not just syntax for a machine — it is the base layer of boundary infrastructure in a codebase. This chapter explains how language mechanisms express design intent, enforce boundaries, and shift the trade-offs of modification under AI-assisted development.
Developers often talk about programming languages as a matter of taste: this one is concise, that one is safe, this one is flexible, that one is fast, this one feels nice to write. Those descriptions are useful, but they miss the design-level point.
A programming language is not just a way to write instructions for a machine. It is the base layer of boundary infrastructure in a codebase.
Software design uses boundaries to cut a large, messy problem into smaller pieces you can reason about independently. Each boundary defines what you need to know on one side and what you are allowed to ignore on the other. Across a codebase, these boundaries separate caller from implementation, public contract from private detail, valid state from invalid state, and local mechanism from system rule.
But boundaries are not all equally strong.
Some boundaries are just team rules: “don’t put domain logic in controllers.” Some are structural: “internal helpers live under this directory.” Some are protected by tests: “this behavior should not change.” These are useful, but they all depend on people remembering the rule and noticing violations.
A programming language is stronger for a simple reason: if you break a boundary it enforces, the program just does not pass. It does not compile, it does not type-check, or the runtime rejects it. The boundary is no longer something developers are supposed to remember. It is part of what makes the program valid.
That is the real design power of a language. Syntax is surface. Boundary enforcement is infrastructure.
1. Languages Turn Design Intent Into Enforced Structure
Before a language can enforce a boundary, it must give you a way to express it. This is where language expressiveness matters.
In this article, an expressive language is not just a language that lets you write less code or use more elegant syntax. It is a language that lets you express more of your design intent directly in the program, using mechanisms the toolchain can check and enforce.
That is the key difference between a language boundary and a convention boundary. A convention can say “this value should not be null,” “this module is internal,” or “this function should not do IO.” A language mechanism can make some of those claims part of the program itself. If the claim is broken, the program does not pass.
This changes the cost of change by moving boundary checks forward. Without enforcement, developers pay the cost later through reading, review, debugging, or failed changes. With enforcement, part of that cost is paid while writing the code. This can feel like friction, but it turns hidden future context into immediate tool feedback.
So the useful question is:
Which important boundaries can this language express and enforce cheaply?
That is where language expressiveness connects to context cost.
2. Language Features Are Boundary Mechanisms
With that framing, language features become easier to compare.
Static types enforce shape boundaries. They let functions, objects, and modules state what kind of data they accept and return, so callers can reason from contracts instead of reconstructing shapes from examples, tests, or implementation details.
Nullability and option types enforce absence boundaries. They make “this value may be missing” part of the program structure, so absence is handled explicitly instead of living as an assumption in the caller’s head.
Enums, sealed classes, ADTs, and exhaustive matching enforce variant boundaries. They let a concept declare its valid cases, and they make consumers acknowledge that case space when handling the concept.
Modules and visibility enforce implementation boundaries. They separate public contract from private detail, so external code cannot accidentally depend on internals that should remain changeable.
Immutability enforces mutation boundaries. It marks which values cannot change, reducing the need to track who may have modified a value before it reaches a given point.
Ownership, borrowing, and lifetimes enforce resource and aliasing boundaries. They make ownership, sharing, mutation, and valid access duration part of the program’s contract instead of leaving them to convention.
Effects, checked errors, and async markers enforce behavior boundaries. They make important behavior profiles visible at the call boundary: whether code may fail, block, suspend, mutate, perform IO, or require a particular execution context.
This is what language expressiveness means in design terms:
A language is more expressive when it can turn more design intentions into explicit, enforceable boundaries.
A feature is not expressive merely because it is clever or abstract. It is expressive when it lets the code say something important about the design, and when the toolchain can help protect that statement.
3. Language Wars Are Boundary Trade-offs
Language choice is like architecture choice. You do not choose the “best” one in the abstract. You choose the one whose trade-offs match the system’s expected modification pattern.
This is why language debates rarely end. People are often arguing from different kinds of systems, where different boundary failures are expensive. Under CMP, these debates become easier to read: each side is defending a different boundary cost.
Static vs. Dynamic: When Should Shape Boundaries Be Enforced?
Static typing advocates have seen what happens when shape boundaries are weak. A field rename, a return-shape change, or a missing case can spread quietly through a long-lived codebase. The larger and more stable the system becomes, the more valuable it is for those shape boundaries to be written down and checked by tools.
Dynamic typing advocates have seen the opposite cost. When the target is still unclear, shapes change quickly. Locking them down too early can slow exploration, because every trial change has to pass through a boundary that may not be stable yet.
So this debate is not really “safety versus flexibility.” It is about timing. Are the important shapes stable enough to deserve language-level enforcement, or is the system still discovering them?
TypeScript is interesting because it sits directly on this boundary. It adds structural shape boundaries to JavaScript, but keeps them gradual and escapable. Its value is not that it makes JavaScript fully safe. Its value is that teams can choose where a shape boundary has become important enough to express.
Ownership vs. Garbage Collection: When Should Resource Boundaries Be Enforced?
Ownership advocates have seen the cost of weak resource and aliasing boundaries: data races, invalid references, accidental sharing, unclear lifetimes. In systems where memory, concurrency, and resource flow are central correctness problems, those boundaries are too important to leave to convention.
Garbage-collected language advocates have seen a different cost. In much application code, resource lifetime is not where most changes fail. Forcing every ordinary change to carry ownership discipline can make the language feel heavier than the problem requires.
Rust is powerful because it makes ownership, mutation, lifetimes, and concurrency boundaries explicit and enforceable. That is the right trade in systems where memory safety, concurrency safety, and resource ownership are part of the core problem: operating systems, embedded software, databases, browsers, game engines, high-performance network services, cryptography, or infrastructure components that cannot afford data races, dangling references, or unclear ownership. It feels expensive when they are not the main source of modification risk.
Pure Functional vs. Pragmatic Side Effects: When Should Behavior Boundaries Be Visible?
Pure functional programming makes a specific bet about context cost. A pure function’s behavior is fully determined by its arguments and return type. To read it, modify it, or reason about whether a change is correct, you do not need to know what state existed before the call, what other code may have mutated in the meantime, what IO was interleaved, what thread it ran on, or what ambient environment it depended on. All of that — temporal context, aliasing context, environmental context, concurrency context — is depth that normally lives outside the signature and is the most expensive kind of depth to reconstruct. When purity is enforced and visible at the signature, that extra depth is compressed to near zero: the function’s context is the function itself.
This is also what makes pure functional style fit best where correctness is hard-won and must be defended under change. Compilers, type checkers, query planners, parsers, cryptographic primitives, financial and pricing engines, rules engines, simulation cores, and formally verified components all share a property: their correctness has to be argued from the code itself, often case by case, and every hidden effect is a place that argument can quietly fail. When each function’s behavior is fully captured by its signature, the verification surface shrinks to something a person, a test suite, or a proof tool can actually cover end to end. Languages like Haskell, OCaml, F#, and Scala — and the “functional core, imperative shell” pattern inside otherwise mainstream codebases — are aimed at exactly this kind of work.
Most mainstream languages — Python, JavaScript, Ruby, Go, Java, C# — sit on the other side by default. They let functions perform IO, mutate state, throw, or call external systems without encoding any of that on the boundary. In typical application code almost every path is effectful anyway, so the extra surface would mostly repeat what the reader already assumes.
So the deciding question is not whether pure functions are nicer, but whether the system pays a high price for unseen behavior depth. In code where a wrong effect is expensive to detect or impossible to recover from, compressing that depth at the language level usually pays for itself. In code where effects are uniform and recoverable, it usually does not.
Minimalist vs. Expressive Languages: How Much Boundary Vocabulary Should the Language Provide?
Some languages intentionally keep the boundary vocabulary small. Go is the clearest example. It trades richer boundary machinery for low ceremony, predictable reading, and fewer concepts every developer must carry. That is a good trade when simplicity and uniformity save more context than stronger enforcement would.
Other languages provide richer tools for expressing design intent. Java puts nominal types, interfaces, and visibility near the center of design. Strongly typed functional languages make variants, immutability, and composition highly expressive. Rust goes further on ownership, mutation, lifetimes, and concurrency.
These languages are not merely more or less “powerful.” They choose different boundary vocabularies. A richer vocabulary lets more design intent become explicit and enforceable, but it also asks the codebase and the team to carry more concepts.
The mistake in language wars is to treat one environment as universal. No language has the right boundary trade-offs for every codebase.
A language fits when the boundaries it enforces are the boundaries your codebase must preserve under change. Stronger enforcement fits better when the target is known and the boundaries are expected to survive. More flexible languages fit better when the target is still being discovered.
So the better question is:
Does this language express the boundaries that matter in this system, and is the enforcement cost worth paying?
4. AI Shifts the Trade-off Toward Expressive Languages
This shift did not begin with AI. AI makes it easier to see.
Over the last decade, the direction of language evolution has already been moving toward stronger boundary expression. Newer languages such as Rust, Swift, Kotlin, TypeScript, Zig, and Gleam all make different trade-offs, but they share a broad tendency: more explicit types, more visible failure modes, more structured state spaces, clearer module boundaries, and stronger tool feedback.
Even dynamic language ecosystems have moved in the same direction. Python added type hints and developed tools such as mypy and Pyright. JavaScript was reshaped by TypeScript. Ruby added RBS and Sorbet. PHP has steadily expanded its type system. These ecosystems did not become purely static languages, but they all added ways to express more design intent in forms tools can inspect.
Under CMP, this is not just a fashion in language design. It is a response to scale. As codebases grow larger and live longer, implicit assumptions become expensive. Teams need more of the system’s meaning to be carried by source-level structures rather than by memory, convention, documentation, or test failures.
AI-assisted development strengthens the same pressure. Agents can write code quickly, but they are sensitive to hidden semantics. A language that exposes more boundaries in signatures, variants, modules, effects, nullability, ownership, or schemas gives both humans and agents a smaller search space and a stronger feedback loop.
Expressive languages used to ask developers to pay two costs directly. One is learning cost: the team has to understand types, variants, lifetimes, effects, visibility rules, ownership rules, and the way these mechanisms shape code. The other is design-commitment cost: once a boundary is expressed in the language, the codebase has to respect it, and related changes have to move through that constraint.
Coding agents can reduce both costs. They already work across many languages, and they can pick up language-specific rules from code, compiler output, type errors, and documentation. They can generate boilerplate, follow compiler feedback, fix type errors, update exhaustive matches, and propagate boundary changes through the codebase. In practice, this makes stronger language mechanisms easier to use.
At the same time, AI makes the benefits of expressive languages more valuable. Agents work better when the codebase gives them explicit constraints. A compiler error is a concrete repair target. A type signature is a compact contract. A failed exhaustive match shows where a change is incomplete. A borrow-checking error exposes a resource boundary the agent must respect.
So AI shifts the trade-off toward expressive languages: the cost of using expressive mechanisms goes down, while the value of explicit, enforceable boundaries goes up.
This does not remove the need for human design judgment. Someone still has to decide which boundaries are worth expressing in the language. But once those boundaries are there, both humans and agents get stronger feedback when they break them. That is why AI-assisted development is likely to favor more expressive languages over time, especially in long-lived systems where correctness under modification matters.
Conclusion: Programming Languages Are Boundary Infrastructure
Programming languages sit at the bottom of a codebase’s boundary system.
When a design boundary is expressed only as intention, developers have to remember it, review for it, and rediscover it during future changes. When the same boundary can be expressed in the language, the codebase can help protect it. The compiler, type checker, or runtime can reject violations before they turn into debugging work, production bugs, or hidden coupling.
This is the role of programming languages in CMP: they move some design boundaries from human discipline into the codebase itself. The more expressive the language, the more of those boundaries can be stated directly in code and protected by tools during future modification.
Part IV — Practice: Design in the Agent Era
Chapter 13
Over-Engineering, YAGNI, and Bad Context Bets
Over-engineering is not too much design — it is a bad context trade. This chapter frames over-engineering and under-engineering as mispriced bets on expected context cost, with static and temporal criteria for when structure pays for itself.
A team is building a B2B SaaS product. Someone proposes a multi-tenancy layer before the product has a second customer: tenant-aware queries, tenant-scoped cache keys, tenant-routed background jobs, tenant-specific reporting. One reviewer calls it clean architecture. Another calls it over-engineering. Both are reacting to real costs, but they are pricing different futures.
This is why debates about over-engineering so often feel unresolvable. The argument is rarely just about whether abstraction is good or bad. It is about whether the context cost paid today is worth the context cost that might be avoided tomorrow.
Over-engineering is not “too much design.” It is a bad context trade: a design move adds context cost — a new boundary, a new concept, a traversal hop, an index to learn — but fails to remove, relocate, or index enough context cost in return.
To judge whether a design decision is worthwhile, it helps to separate two scenarios. In the first, the relevant modification stream — the kinds of changes we expect to make — is already known or highly constrained, and judging the design is close to an accounting exercise. In the second, we are working in a living system, where future requirements are uncertain and the design decision becomes a wager rather than an accounting entry.
1. The Static Criterion: When the Change Is Already Clear
Start with the easy version: suppose we already know what kind of change is coming. Maybe we know this service will need three payment providers. Maybe we know this import pipeline will support ten file formats. In that case, we can ask a very practical question:
Does this design pay for itself?
Abstractions, layers, interfaces, registries, configuration, and design patterns are not automatically good or bad. They are worth adding only when they save more context than they force the next engineer to load.
A design move usually adds cost in three ways:
- Boundary cost — Every abstraction gives engineers a new interface to learn: names, inputs, outputs, error behavior, invariants, and edge cases. A good boundary pays for itself by letting people stop there instead of reading the whole implementation. A bad boundary is shallow: the interface costs nearly as much to learn as the implementation it hides, so it barely shrinks the total context you have to load. This is the same intuition behind Ousterhout’s deep versus shallow modules in A Philosophy of Software Design.
- Carrying depth — Some design choices become a toll booth that many future changes must pass through, even when those changes do not benefit from the design. If every database query goes through a multi-tenant routing layer, then even a simple internal report now has to understand that layer. The setup cost is not paid once; it is paid every time someone touches nearby code.
- Conceptual surface — Some designs add vocabulary to the codebase: new concepts, rules, conventions, registries, generated files, or “the way we do X here.” Even engineers working on unrelated features may need to know that vocabulary during naming, refactoring, review, debugging, or onboarding. For example, once a codebase adopts its own error-handling convention — say, a custom Result type that every function is expected to return and every caller must unwrap — engineers have to carry that vocabulary even when working on features that have nothing to do with why it was introduced.
Those costs are fine if the design removes bigger costs elsewhere. The usual ways a design earns its keep are:
- Depth skipped — A reliable interface lets you read the contract and avoid reading the internals.
- Closure collapsed — A repeated change pattern gets pulled into one place, so future changes no longer require hunting through scattered sites.
- Closure indexed — The related sites may still be distributed, but they become easy to find through a registry, exhaustive match, generated artifact, naming convention, or just comments.
- Implicit context checked — Tests, types, and language mechanisms catch assumptions that would otherwise live only in people’s heads.
So the static rule is simple:
A design move is justified when the context it saves, collapses, indexes, or checks is larger than the boundary cost, carrying depth, and conceptual surface it adds.
2. The Temporal Criterion: When the Future Is a Bet
The previous rule works when we know the shape of future changes. Most real codebases do not give us that luxury. We often add structure because we think a future requirement might arrive.
That makes design under uncertainty closer to a bet than to an accounting exercise. We pay a visible cost now for a benefit that may or may not show up later. Over-engineering is what happens when that bet is overpriced.
The clean way to reason about this is to compare two worlds.
In the build-now world, we add the structure today. Suppose the team builds the multi-tenancy seam now: every query, cache key, background job, report, and session path becomes tenant-aware. From now on, engineers have to carry that model while working in the codebase. The payoff arrives only if the future SaaS requirement appears in roughly this shape.
In the defer world, we do not build the seam yet. The code stays single-tenant and direct. We avoid today’s carrying cost. But if SaaS arrives later, someone has to find every place that assumed one tenant: queries, cache keys, URL routing, sessions, reports, tests, logs, permissions, deployment assumptions, and so on.
The question is not “is abstraction good?” The question is:
Is the future context cost we avoid likely to be larger than the present context cost we pay?
YAGNI is the right call when the future change is unlikely, small, local, or easy to solve later. Building structure early is the right call when waiting would leave a large, scattered, hard-to-find set of assumptions for the next engineer to recover.
Two risks matter here.
Wrong-shape risk is the risk of building the wrong seam. Maybe we add a row-level tenant_id model, but the real requirement later needs physical tenant isolation. In that case, the abstraction did not buy us the future we paid for. Worse, it may become extra machinery that future work must route around.
Unindexed-closure risk is the risk of deferring too casually. If every query and cache key quietly assumes one tenant, the single-tenant decision is already spread across the system. If nothing names or indexes that assumption, a future retrofit is hard not only because there are many places to change, but because the engineer does not know when the search is complete.
These risks pull in opposite directions. Wrong-shape risk warns us not to build too early. Unindexed-closure risk warns us not to let important assumptions leak everywhere unnamed. YAGNI and the Rule of three are useful because they help calibrate this timing: wait long enough for the real shape to appear, but not so long that the decision becomes invisible and scattered.
That gives us four common outcomes:
- Justified eager structuring: The structure costs something now, but it avoids or indexes a larger future modification closure.
- YAGNI-correct deferral: The future change remains small, local, or discoverable enough that building structure now would cost more than it saves.
- Over-engineering: The interface burden, carrying depth, conceptual surface, and wrong-shape risk are larger than the future cost actually avoided.
- Under-engineering: Today’s simplicity leaves a realistic future change scattered and unnamed, making the necessary context expensive or unreliable to recover later.
Good design is not “more abstraction” or “less abstraction.” Good design pays visible cost only where it makes present or future changes cheaper to understand.
Under-engineering is the mirror image of over-engineering, and it can hide behind an equally attractive slogan. Over-engineering often presents itself as “clean architecture” or “future-proof design.” Under-engineering presents itself as “simple and reliable”: fewer abstractions, fewer moving parts, less machinery to explain. That can be exactly right when the future change is small or unlikely. But it becomes under-engineering when “simple” code quietly spreads an important assumption without giving future engineers a name, index, or check for it. The code feels easy today because no abstraction was added and everything works. The future modifier pays the hidden bill later: they must rediscover where the assumption lives, what depends on it, and where the change is allowed to stop.
3. Making Hidden Costs Easier to Talk About
This criterion will not give you exact numbers. You usually cannot calculate the probability of a future requirement, or the exact cost of a retrofit. That’s fine, though — precision was never the goal. What matters is making the trade visible.
Many design debates get stuck in taste labels:
- “This is clean architecture.”
- “This is over-abstracted.”
- “YAGNI.”
- “We need to make it extensible.”
CMP turns that argument into two separate questions:
- Prediction question: What future change does this design assume? Are we betting on more tenants, more payment providers, more file formats, stricter compliance, higher traffic, or some other modification stream?
- Design question: If that future actually happens, is this design a good way to handle it? Does it save, collapse, index, or check more context than it adds through boundary cost, carrying depth, and conceptual surface?
This split matters because teams often argue about design while silently assuming different futures. One engineer may be evaluating the multi-tenancy layer under the assumption that SaaS is likely. Another may be evaluating the same layer under the assumption that the product will stay internal. They are not really disagreeing about the code yet; they are disagreeing about the prediction behind the code.
Once the prediction is explicit, the design debate becomes more concrete. Under this future assumption, does the design pay for itself? If yes, it may be justified eager structuring. If no, it is over-engineering even if the future does arrive. If the future assumption itself is weak, YAGNI is probably the better call.
Many architectural disputes are arguments about the future disguised as arguments about design style. Over-engineering and under-engineering are not style problems. They are two ways of mispricing context: paying too much too early, or calling it “simple and reliable” while leaving too much unnamed for later.
Chapter 14
How Cheap Code Rewrites Design Bets
When agents make code cheap to produce, the cost-benefit math behind every design decision changes. This chapter explains what actually got cheap, what stayed expensive, and why practices that once looked like over-engineering can flip to positive ROI.
A frontier coding agent today bears almost no resemblance to the autocomplete of a few years ago. Give it a real task and it will work largely on its own — exploring an unfamiliar codebase, editing across many files, running the tests, reading the failures, and iterating for hours until they pass. These agents are already strikingly capable, and they are getting better fast.
The result is a real shift in where the work happens. The default mental model is no longer “open an editor and write code”; it is closer to “express intent, delegate it, and review what comes back.” Writing the code — the activity that used to define the job — is increasingly the part you hand off.
From here an obvious conclusion suggests itself, and plenty of people have drawn it. If code is this cheap to produce, does the careful practices we used to ration — architecture design, exhaustive tests, strict types — still matter now. Why invest in keeping code easy to change when you can simply regenerate it?
The most common complaint about these agents points the other way. Across the industry surveys, the defining frustration is not that agents fail to produce code; it is that the code is almost right — fluent, plausible, and subtly wrong. It compiles, it passes the happy path, it reads like something a competent engineer would write, and it still does the wrong thing at an edge the agent never considered. Producing code became cheap. Knowing whether that code is correct did not — which is why most teams still hand-review every change an agent proposes.
That gap is what this chapter is about. The previous chapter framed over-engineering and under-engineering as two ways of mispricing context: paying for too much structure too early, or leaving too much unnamed for later. Capable agents do not overturn that framework; they move the prices that feed it — and they move them unevenly, making some long-dismissed practices suddenly worth it while leaving others as wasteful as they ever were. To see which is which, we have to be precise about what actually got cheap.
Why not just keep the spec?
Take that last question literally. Its most radical form does not just say skip the tests; it says stop maintaining code at all — keep a spec, regenerate the code on demand, and treat the code as disposable build output, the way we already throw away the binary a compiler emits. If that held, there would be no standing artifact to design for, and this chapter would have no subject.
It does not hold, and the compiler analogy is exactly where it breaks. We throw binaries away safely only because compilation is deterministic, behavior-preserving, and local: the same source always yields the same binary, the translation never alters what the source already pinned down, and a one-line edit perturbs one place. Generating code from a spec has none of these properties — so calling the model a “compiler” smuggles in guarantees it does not provide. The reason traces to one stubborn fact: a spec never fully pins down the code. Whatever it leaves unsaid, the model fills in — plausibly, but under-determined — and regeneration has no memory. Every run re-rolls each decision the spec does not fix. The behavior you validated last time through real use — the edge case from production, the default that turned out to matter — gets thrown back in the hat and re-sampled. Patch the spec to fix what came out wrong, regenerate, and what was right last time can quietly drift. You buy stability only by writing down more, until the spec pins almost everything.
But a spec that pins down everything is the code — just in a vaguer notation, “compiled” by something neither deterministic nor local.
So the code does not go away. The precise, accumulated record of every decision we have nailed down has to live somewhere, and its most honest home is still the code. It persists — so the central act is modifying that standing artifact, not regenerating it from nothing. This is the bedrock CMP rests on: design exists for modification, and there is something to modify only if the artifact stays. So the real question is no longer whether to keep code, but what — now that an agent does the typing — actually got cheaper.
What just got cheap
It is tempting to say agents made “writing code” cheap, but that is not quite the boundary. Plenty of things involving code are still slow and painful, and a few things that have nothing to do with typing characters became nearly free. The real line runs somewhere else.
What collapses toward zero is any task where “right” has a checkable reference — something the agent can hold its work against and judge itself by, instead of waiting for a person to say.
That reference is broader than a test suite. Sometimes it is a mechanical judge the agent can run at will — a compiler, a type checker, a failing test, a linter — and then it gets the strongest version: a closed feedback loop, where it acts, reads the verdict, corrects, and repeats with no human in between. But just as often it is a concrete target to match: an existing pattern in the codebase to follow, a reference implementation to port, a worked example, a spec precise enough to pin the answer. Wherever a known-good target exists, the agent turns into a tireless generate-and-check engine and converges on it far faster, and far more patiently, than a person — which is exactly why it feels so strong at scaffolding, conventions, and translations, and so much shakier the moment the target goes fuzzy.
So the useful question about any cost is not “does this involve code?” but:
Does this task come with an oracle — a test, a reference, a target — that says whether the work is right yet, without a human having to decide?
Run the same question across the demos that actually go viral — not the modest ones — and the shape is identical:
- An agent one-shotting a playable game — a Snake clone, then a side-scrolling shooter — oracle: it runs, and countless existing implementations already spell out what such a game should be, an endless supply of reference to imitate and check against.
- Rewriting a system as large as Bun in Rust — oracle: the original runtime itself, diffed behavior for behavior, its existing test suite carried over wholesale. The target is enormous, yet completely pinned down.
- Solving a Rubik’s cube, or any well-posed puzzle — oracle: the solved state, decided mechanically.
These read as raw intelligence, but that is not what they share. A weekend rewrite of Bun and a one-line compiler fix have nothing in common in scale or difficulty — only that in each, “right” is pinned down somewhere the agent can reach and re-check on its own. Impressiveness here is a symptom of verifiability, not a counterexample to it. None of these got cheap because “writing” got cheap, or because the agent simply “knows more.” They got cheap because each one comes with a target the agent can check itself against, as many times as it likes. The common thread is verifiability — and the tighter and more automatic the check, the cheaper the task. That is what AI made abundant: once “right” is pinned down sharply enough to check, covering the distance to it is nearly free — the agent will get there on its own.
What stayed expensive
The same law, read from the other side, tells you exactly what did not get cheaper.
A problem with no automatic oracle did not get cheaper. And because agents now produce far more change, far faster, the absolute amount of this kind of work is going up, not down.
If nothing can mechanically tell the agent it is wrong, the loop never closes on its own. The agent will still produce something — fluent, plausible, and delivered with the same confidence as the correct version — but “looks done” and “is correct” have come apart, and only a human can tell them apart. This is where the expensive work now lives:
- Whether a change is actually correct, when no test exercises the behavior it touched.
- Design-level errors: a boundary drawn in the wrong place, a concept that does not match the domain, a modification closure left half-changed.
- Misread intent — the agent confidently solved a slightly different problem than the one that mattered.
- The semantic and judgment calls that only surface in human review.
You can feel the same wall outside code entirely — it is how this very chapter got written. There is no oracle for prose: no test goes green when a paragraph finally lands, and nothing can diff a sentence against a known-good answer. So the drafts came fast and fluent, but getting each section right took round after round, paragraph by paragraph — a plausible version proposed, read, judged not quite, and reworked, sometimes over several passes before one held. Producing the words was never the bottleneck; deciding which version was actually right was, and only a human could settle it. It is the same wall an agent hits on a subtle correctness question in code, met from the other side.
The expensive residue is convergence to correct when nothing automatic can tell you that you are wrong. That, not typing speed, is the real ceiling on how much you can trust an agent’s output — and it is exactly the almost right problem, seen from the design side.
The practices that attack the expensive part
Step back, and the last two sections collapse into a single, old distinction: what to do versus how to do it. The how is what got cheap, and it keeps getting cheaper from stronger models, and richer harnesses. Each advance makes how less and less of the problem. The what part of the question stayed expensive, and neither models nor harnesses touch it: defining what to build, and what counts as right, is the part that stays with a human. There is no oracle for it but us.
That points to where the design leverage is. Deciding what counts as correct is a human act; the leverage is in capturing each such decision the moment it is made and writing it down in a form an agent can run — a test, a type, a contract. The judgment happens once; from then on, checking that the code still honors it is cheap and automatic, on every change the agent makes. So the highest-leverage thing a codebase can do is bank those settled decisions as executable checks — turning correctness a human would otherwise re-verify by hand, on every change, into something the agent verifies on its own.
This is not a new category of technique. It is a precise description of practices we already have — and have spent years arguing about:
- Tests and TDD take behavioral correctness, otherwise checkable only by a human reading carefully, and make it executable. A covered behavior now has an oracle, so a regression in it falls into the cheap region: the agent sees the red test and self-heals.
- Strong typing takes a chunk of the modification closure — the “what else must change when this changes” that breadth is about — and makes omissions mechanically visible. Change the type, and the compiler enumerates the sites you forgot. A whole class of “the thing you forgot to change” stops being silent.
- Architecture is the same move at its largest grain. How a system splits into parts, what each part owns, and which parts may depend on which is a human’s call about the what — structural design intent that carries no oracle on its own. Written down as enforceable boundaries — dependency direction, module visibility, the contract at each seam — that intent becomes mechanically checkable: a change that reaches across a boundary it should not, or points a dependency the wrong way, trips a check instead of waiting to be caught in review.
- The rest of the toolkit — assertions and contracts, property-based tests, exhaustive matching, schema validation — are the same move under different names: take an assumption that used to live only in someone’s head and make it executable, so violating it produces a signal instead of a surprise.
Each of these does the same thing in CMP terms: it converts context that could previously be checked only by an expensive human pass into context that a cheap automatic loop can check. It drags correctness from the expensive side of the border to the cheap side.
None of this is new — these are the same practices we have always had. What an agent changes is their price, and the clearest way to see it is to set the old trade from the previous chapter beside the new one, term by term.
In the human-only era, the cost of these practices was dominated by human labor: writing and maintaining the tests, learning and satisfying the type system, fighting the compiler. The benefit — fewer silent errors later — was real but deferred and diffuse. For a great many teams the visible present cost beat the diffuse future benefit, and the honest verdict was YAGNI. Skipping them was often the correct context bet.
Two of the terms in that bet have now moved:
- The cost side fell. Writing the tests, adding the annotations, satisfying the checker — these sit squarely in the cheap region, because each one comes with its own oracle. The agent absorbs most of the labor that used to make these practices “too much trouble.”
- The benefit side rose. The payoff of these practices was always “an automatic signal when something is wrong.” That signal used to be a nice-to-have for humans who could. It is now the scarce resource — the one thing that decides whether an agent’s torrent of cheap changes is trustworthy. The benefit is no longer diffuse and deferred; it is the difference between a change you can merge and one you must stop and hand-audit.
When a practice’s cost falls and its benefit becomes the scarce resource, its ROI does not inch up — it flips. What was over-engineering for a human-only team can be the right call when the primary modifier is an agent. The taste did not change; the modifier did, and the prices followed. One caveat rides along: now that checks are cheap to manufacture, the scarce virtue is no longer writing them but deleting the ones that carry no signal — a flaky or tautological check is worse than none, because the agent will dutifully close the loop against a lie.
The predictions
A framework that only explains is a story. One that predicts is a bet you can lose. The mechanism this chapter isolated is sharp enough to make those bets: AI collapsed the cost of any correctness that comes with an oracle and left everything else priced exactly where it was. Read that one law forward and it makes specific calls about where the industry goes — each forecast below follows from it, and the set is meant to be testable, with clear ways the next few years could prove it wrong.
Typed languages win back the center. TypeScript over JavaScript, Rust into systems work, the rapid retrofitting of gradual types onto Python and Ruby — adoption climbs fastest exactly where agents do the most writing, because a type is at once the cheapest oracle to manufacture and one of the most precise — it pins a decision down exactly, with no ambiguity left for the model to re-roll, and makes the modification closure mechanically visible. Dynamic ecosystems respond by bolting static layers on, and the direction of travel is one-way. The falsifier is clean: if a decade out the dominant agent stack is untyped and thriving on it, this chapter was wrong.
Architecture’s payoff moves to separating the what from the how. The most valuable thing design does at this grain is draw a clean line between the decisions that carry an oracle and the ones that never will — isolating the what to do, where only human judgment settles what counts as right, from the how to do it, where an agent can check itself and converge. A system carved along that seam hands the agent wide territory it can work cheaply and verify on its own, while concentrating the expensive, un-oracled judgment into a small, legible surface a human can actually hold. Whether those boundaries are also mechanically enforced matters less than where they are drawn: architectures that make the what/how split explicit see their return jump, and ones that smear the two together across every module leave a human auditing everywhere at once.
Spec-driven design plateaus, because code is the most precise spec there is. The spec-first orthodoxy puts all its weight on the document as the artifact that matters, and that is the wrong bet. A spec in prose pins down what to do only loosely; whatever it leaves unsaid, the model re-decides on every run. The most exact and complete expression of intent we have is the code itself. So the forecast is that attention spent on the spec alone stalls exactly where the spec stops fixing the answer, and the pattern that lasts pushes intent into the code as executable form, treating the code as the canonical what and the spec as a lossy view of it.
An oracle-manufacturing industry forms. Contracts, property-based testing, runtime assertions, schema validation, executable architecture checks — tooling whose entire job is to convert a human judgment into an automatic signal becomes a category with its own budget line and its own venture thesis. What it sells is the one resource AI made scarce: output you can trust without reading every line.
The codebase becomes the moat. Give two teams the same models, the same agents, and the same headcount, and they diverge on the only thing that matters — how much of the agent’s output they can merge without a human audit. The differentiator is the verifiability of the codebase, and a better model does not close the gap. Expect that property to get measured: a verifiability metric on the CI dashboard, in technical due diligence, in the honest valuation of what an acquisition’s code is actually worth.
The engineer’s job concentrates on the un-oracled half. As the how falls to the agent, the work that stays human is deciding what to build, defining what counts as right, and catching the almost right. Hiring, titles, and seniority tilt toward specification, boundary design, and review. Implementation as a standalone role — typing code from someone else’s specification — fades out, because that half of the work now belongs to agents.
One last bet rides on top of all of them. Once checks are cheap to mass-produce, the scarce skill flips from writing them to deleting the ones that lie. Flaky and tautological checks become a dominant failure mode, and managing the signal-to-noise of the check suite turns into a named discipline.
Every one of these reduces to the same claim, now stated as a forecast rather than an observation: the worth of a codebase is migrating toward how much of its correctness an agent can verify on its own. Reliable coding agents need better codebases — and the next few years will make that concrete, team by team, settled by who can trust what their agents ship.
Chapter 15
Clean Architecture Revisited: From Overhead to Leverage
Clean Architecture was always strong context-control design; what held it back was ceremony cost. This chapter reads CA through CMP — policy vs. mechanism, placement, and the Dependency Rule — and explains why agents flip its ROI.
I have always liked Clean Architecture. And in the age of AI coding, I think its advantages have become hard to ignore: judged against CMP’s own yardstick — does a design make the sufficient context for realistic modifications cheaper to acquire? — Clean Architecture satisfies nearly everything the principle asks for. It was always good context-control design. What held it back was its price: too high for most teams to collect the payoff. And agents cut that price — exactly what CA’s structure rewards.
So the chapter does one thing: it reads CA through CMP, dissolving the concentric-ring diagram into a single mechanism — the separation of policy from mechanism, manufactured by one design discipline, placed by the layout, and protected by one invariant. Seen this way, Clean Architecture is a battle-tested embodiment of what CMP recommends: it lowers the cost of acquiring the sufficient context for the modifications a system actually faces. And the work that earned CA its bad reputation — the ceremony — is exactly the cheap, checkable labor an agent now carries for free.
1. The one boundary CA is really about: what vs. how
Figure 1. Clean Architecture’s concentric rings
Clean Architecture exists to separate policy — what the system should do, from mechanism — how it gets done. This single what/how line is the protagonist of the whole chapter. Layers, the dependency rule, ports, adapters, testability — each exists to manufacture that line, place things on the correct side of it, or keep it trustworthy. Hold onto that.
The use case: cutting one process into independent sub-problems
CA’s primary tool for drawing the line is the use case, and the move it makes is worth slowing down on. A use case takes one business process — “place an order,” “issue a refund” — and splits it into two things that change for different reasons. First, an outline: the ordered narrative of what the process does, in domain language — validate the cart, reserve inventory, charge the customer, record the sale, notify. Second, a set of ports: one named hole for each concrete capability the outline calls on — InventoryReservation, PaymentGateway, SalesLedger. The outline is policy: it owns the what and the order. Each port is a seam, and the how behind it — Stripe, Postgres, a queue — stays out of scope while you read the process.
The payoff is decomposition. One tangled process becomes a short, readable policy narrative plus a handful of independent sub-problems, each sealed behind its own port, or another smaller use-case. You can grasp the whole what from the use case alone, paying nothing for details of how; and you can rework any single how — swap the payment provider, re-tune persistence — without touching the outline or the other ports. A complex business process stops being one monolith you hold in your head all at once and becomes a set of small problems you route to and solve one at a time.
The entity: why a static object can carry a business rule
The other half of the policy core is the entity, and here CA trips up almost everyone new to it. Entities carry Enterprise Business Rules — the rules true of the business itself, independent of any application. But a rule feels like behavior, while an entity looks like a static object: a bag of fields with getters. How can a noun hold a rule?
The confusion dissolves the moment you stop reading a business rule as a procedure and start reading it as a constraint on which states are allowed to exist. That reframing is the gift of Domain Modeling Made Functional: model the domain so precisely that illegal states become unrepresentable. A surprising share of “rules” are really statements about valid values —
- “an order always has at least one line item” → a type that cannot be constructed empty;
- “you may only ship to a verified email” → verified and unverified as two distinct types, not a boolean flag, so
ship(VerifiedEmail)is the only call that type-checks; - “an order total is never negative” → a constructor that refuses the bad number.
Read this way, the entity earns its place as the guardian of an invariant: its static shape is the rule, because the rule is exactly a description of which values count as a valid instance — and a type is exactly a description of a set of valid values. The “dynamic” rules — place a draft order, apply a discount — are then functions that carry one valid state to another (Draft → Placed), each permitted only the transitions the business allows. Behavior is the set of legal moves between states that are valid by construction. (Domain Modeling Made Functional makes this vivid in FP terms, but the principle is not functional-only: a private constructor that validates its invariant, plus value objects, does the same job in an OO codebase.)
This is why enterprise rules sit in the innermost ring. An invariant the entity enforces on itself cannot be broken by any use case, controller, or ORM mapping downstream — no code path can manufacture an illegal order. Putting the rule in the type means every outer layer inherits it for free: the deepest, most reused, slowest-changing policy a system owns.
Use cases and entities define the policy side; whatever they hold behind a port is mechanism. With the core named that way, the everyday question becomes classification: for a given piece of existing code, which side does it belong on? The signals are stable enough to write down.
| Ask of the code | Policy (route inward) | Mechanism (route outward) |
|---|---|---|
| Why would it change? | A business decision changed | A tool, vendor, or delivery detail changed |
| Could you explain it to a domain expert? | Yes, in their language | No, it is an implementation concern |
| Does it survive a framework swap? | Yes, unchanged | No, it is the framework |
| Is it true regardless of how data is stored or shown? | Yes | No |
When the answer is mixed — “this validation is a business rule and a database constraint” — you have found a decision that is currently smeared across the boundary. That is not a nuisance; it is the exact place CA earns its keep.
2. How CA manufactures the boundary: inside-out order → client-authored ports
Boundary Principles: Hiding Context, Not Code already settled what a good boundary requires: a contract authored by the client, naming what the use case needs rather than what the vendor happens to offer. When the contract is client-shaped, LSP, ISP, and OCP arrive as consequences. What that chapter leaves open is procedural: what actually makes you author from the client’s side, with the SDK sitting right there?
CA’s answer is its entity → use-case → adapter ordering. You design the policy core first, in its own language, with no database or framework in scope. By the time you need persistence or a payment provider, the use case has already written down what it wants — so the port is authored by its client, and the adapter has to satisfy it. The ordering is the discipline that forces client authorship. Reverse it, start from the vendor SDK, and you get provider-shaped wrappers with a clean-sounding name: nominal boundaries that hide code without hiding context.
Clean Architecture gives that principle a concrete execution mechanism. Dependency Inversion hands authorship to the client; inside-out order is what makes you point it the right way every time, instead of only when someone remembers to. That is why substitutability and segregation read as consequences in a CA codebase: the order manufactures the client-shaped contract they rest on.
3. How CA places a change: the two axes that route context
Placement is the locality question: when a change arrives, can you reach its whole modification closure from any natural entry point — an endpoint, a failing test, a domain rule — without searching the tree? CA answers with two axes that together form a coordinate system for routing.
Layers are the horizontal axis. They sort every artifact by its distance from policy — domain rule, repository port, adapter, transport — so once you are holding a piece, you know what kind of thing it is and which side of the line it sits on. The index is real, cheap, and lintable. What a layer alone cannot tell you is which feature owns a change, because a feature change — “add a promo code,” “support partial refunds” — is a vertical slice that cuts across every layer at once.
The use case from §1 is the vertical axis. It is one coherent piece of application behavior, so a modification shaped like that behavior lands in a single owner: the policy in the use case, at most a line on a port contract, the mechanism untouched behind the port. The use case is the address a feature routes to; the layer is the secondary sort once you are inside it. Cross the two and a change has a coordinate — this owner, that layer — instead of a scatter across a controller, an ORM mapping, and a serializer. That is the locality payoff, and it is why an agent can stop searching: it enters one cell of the grid, not the whole repository.
CA builds the grid; it does not place the lines on the vertical axis for you. Which behaviors group into which use case, where one feature ends and the next begins — that carving is the core work of domain modeling: bounded contexts, the shape of the business, the same expensive, un-oracled judgment as “where the what/how line falls” in §1. It is exactly the decision an agent cannot make in your place. CA gives ownership a home — a first-class use-case unit to hang a vertical slice on — then indexes it with layers and protects it with the Dependency Rule. It supplies the container, not the judgment.
4. How CA protects the boundary: the Dependency Rule as a routing oracle
A boundary is only worth its cost if it is trusted. An untrusted boundary degrades into nominal indirection — a layer you still have to cross to be sure. The Dependency Rule (source dependencies point only inward) is the single global invariant behind that trust: the policy core never imports a framework, a database client, or a transport type. Its reach is deliberately narrow: it checks the direction of dependencies, not whether the boundary sits in the right place or whether the port is client-shaped — a perfectly inward-pointing graph can still surround a badly-drawn boundary. What it guarantees is narrower and real: a boundary you did draw well does not quietly rot.
Architecture as Context Routing gives the failure mode its real name: architectural corrosion is routing failure. One inward leak — a domain rule parked in a controller, an ORM type imported into an entity — does local damage and teaches every future modifier that the boundary can lie. Once a boundary can lie, people route around it: they search both inside and outside the official path, and the architecture now charges full carrying depth while delivering none of the search reduction it promised.
What lets this guardrail actually hold is that it is mechanically checkable. Dependency direction is structure, and structure can be linted: a check that fires on the leak itself, the moment a source file points the wrong way. Of everything CA asks for, this is the one rule that needs no human judgment to enforce — it never waits on a reviewer to notice, and it never erodes with familiarity. Run on every change, the Dependency Rule becomes an executable routing oracle, so the boundary stays trustworthy by construction rather than by vigilance.
5. Why it was dismissed, and what agents change
Everything in §2–4 was real value the whole time. The dismissal was never about the design being bad; it was about the price. CA’s cost was manual ceremony — mappers, DTOs, ports, wiring, parallel models — paid by a team’s scarcest resource (human attention), against a benefit that was deferred and probabilistic (most apps never swap their framework or database). For most teams, most of the time, the honest verdict was YAGNI.
Agents move two terms of that bet, and they move them in opposite directions:
- The cheap half: ceremony collapses. Mappers, adapters, wiring, and scaffolding are the oracle-checkable region from the previous chapter — work with a clear target to match, which is exactly what an agent does tirelessly and well. The labor that made CA “too much trouble” is now the part you delegate.
- The expensive half: CA targets what did not get cheap. The previous chapter’s headline example of un-oracled, still-expensive judgment was literally a boundary drawn in the wrong place — the payment seam built around swapping providers when the variation that actually arrived was payment semantics (BNPL, subscriptions, regional compliance), leaving every real change to pierce or route around it. Placing that line is CA’s one job. CA does not make that judgment cheap. It makes it reusable, concentrated, and legible:
- Pay the judgment once, then amortize. Deciding what is policy, what the port promises, where the line falls — CA front-loads it into stable structure, so every later change inherits the answer instead of re-deriving it.
- Quarantine the irreducible. Business-rule correctness has no automatic oracle. CA concentrates that un-checkable judgment into a small, pure, framework-free policy core instead of letting it scatter across controllers, ORM, and serialization.
- Route scarce attention. The what/how split tells you where to spend it. The what — the entities and use cases — is where business correctness lives, the part no test fully pins down. An agent may well write that code, but it is worth a line-by-line review: the diff is small, and with mechanism noise stripped out it reads in plain domain terms. The how behind each port answers only to its contract, so you can hand it to the agent to build it automatically. Review goes to the handful of lines that decide what the system does; the how is delegated wholesale to the agent under TDD.
That is the turn. The boundary, the inside-out order, and the placement rules are precisely the machinery that separates the expensive, un-outsourceable judgment from the cheap, fully delegable work — and agents are what finally make the cheap half free.
6. Where CA fits: a wider range, not a universal default
None of this makes CA the right default everywhere. It pays off only when there is a real what/how boundary to draw. Force layers onto a thin CRUD app that has none and CA just scatters a one-field change across files a vertical slice would keep together — and cheaper agent-written hops do not fix the wrong shape.
What agents move is the break-even point, not the test for when CA fits. They make the ceremony cheap to produce and turn its automated checks into what keeps generated code trustworthy — so CA starts paying off at a lower level of domain complexity than before, and the range of systems worth the structure grows. The test itself is unchanged: does this architecture route context along the changes the system actually gets? Answer that first — by looking at the real stream of modifications — and only then draw the boundaries.
7. The general move: re-pricing the designs we called over-engineering
Clean Architecture is one worked example of a larger pattern: a genuinely good practice whose execution cost kept most teams from collecting its payoff, made worthwhile once an agent absorbs that cost. The same lens can surface other lessons software engineering had quietly shelved. Take any discipline once filed under good idea, too expensive, state what it actually buys in CMP terms — cheaper context for the changes a system really faces — then check whether agents have moved its price. Property-based testing, formal specification, mutation testing, documentation kept in step with the code — each is a candidate: a sound bet that lost on execution cost, not on the judgment it front-loads, and now worth a fresh look once an agent carries that cost.
And Clean Architecture is unlikely to be the only case. Decades of software-engineering craft were judged under cost assumptions that no longer hold, so some of what we shelved as too expensive may be worth a second look under the new economics — what an agent now makes cheap, and what it still cannot.
Chapter 16
Post-Task Design Reflection
Solving the reliability problem of AI programming through context routing. This chapter explains why agents can erode codebases, and how post-task reflection turns each modification into locality repair, boundary guards, and ownership signals.
Solving the reliability problem of AI programming through context routing.
1. The Fear: “Will AI Turn My Codebase Into a Mess?”
As agentic engineering moves from demos into real codebases, one fear keeps coming back:
Will AI slowly turn my codebase into a mess?
This fear has become concrete. Teams have started to recognize the pattern in their own repositories. A feature ships faster. A bug gets patched quickly. A test turns green. The immediate task looks done. Then, a few weeks later, the codebase contains one more awkward helper, one more near-duplicate branch, one more special case, one more path that bypasses the boundary the architecture was trying to protect. Each individual change can look reasonable. The damage comes from accumulation.
Recent evidence gives a qualified yes.
A 2026 large-scale study tracked 304,362 verified AI-authored commits across 6,275 GitHub repositories, covering Copilot, Claude, Cursor, Gemini, and Devin. It found that more than 15% of commits from every assistant introduced at least one detectable issue. Most were code smells, but runtime bugs and security issues also appeared. More importantly, 24.2% of tracked AI-introduced issues still survived at the latest repository revision, with unresolved issues accumulating past 110,000 by February 2026.
That is enough to answer the practical question. AI agents can absolutely make a codebase messier when their changes enter faster than the codebase can absorb, review, and repair them.
The point is not that 2026 agents are bad. They are getting more useful, more autonomous, and more embedded in real workflows. That is exactly why the risk matters more. DORA’s 2025 framing is the right one: AI amplifies the surrounding engineering system. If a codebase already has weak locality, unclear boundaries, and missing ownership rules, stronger agents will not magically preserve the design. They will move more code through those weak paths.
This is the dark side of vibe coding. The beginning feels fluid. The ending can become vibe sloping: the system slides from momentum into slop. The speed is immediate. The debt compounds.
So the fear deserves a direct answer.
Yes, AI can make a codebase messier over time.
2. The Current Explanations Are Still Fragmented
There is no single accepted explanation for why agentic coding creates reliability problems. The current literature and industry writing point to several adjacent failure surfaces.
Anthropic’s 2025 work on context engineering explains the problem as context reliability: agents need a small, high-signal working context, because long context can still become noisy, polluted, or hard to reason across. Trajectory-level research on software-engineering agents explains it as workflow reliability: successful agents balance exploration, fix generation, and testing, while failed runs fall into repetitive loops, poorly validated fixes, or weak use of tool feedback. Failure-pattern studies of coding agents explain it as codebase awareness: agents struggle with business rules, shared state, existing helpers, refactoring obligations, and error handling as applications grow.
Industry reports add two more angles. Code review and quality-control discussions focus on review overload: agentic coding makes large diffs cheap, so teams need to decide what humans should review instead of inspecting every implementation detail. Architecture research on “vibe architecting” focuses on governance: agents now make framework, decomposition, integration, and boundary decisions that often arrive inside a working patch without an explicit design review.
These explanations are useful because they expose different aspect of the same problem: context, trajectory, codebase awareness, review load, and architecture governance. They are not separate boxes. Trajectory failures and governance failures often appear precisely because the agent did not receive the codebase awareness needed to act within the system’s design. CMP gives us a more compact way to connect them: agentic reliability is a context routing problem.
The question is not only whether the model is strong enough. It is whether the codebase and its surrounding engineering system help the agent find the right information, modify the right place, respect the right constraints, and learn from the right feedback.
3. Why This Is a Context Routing Problem
An agent never modifies a codebase from a complete map. It starts with a request, gathers context, follows names and files, chooses a patch location, runs checks, interprets feedback, and stops when the task appears done. Each step depends on what the codebase makes visible and what it hides.
When the right files, tests, docs, and conventions are easy to discover, the agent can work with a small, high-signal context. When they are scattered or implicit, the agent either misses critical information or compensates by loading too much. That is the context problem.
When the agent can understand how the codebase works as a system — where behavior is defined, how state flows, which business rules constrain the change, what abstractions already exist, which files must evolve together, what boundaries protect the design, and what conventions the codebase expects — it can make changes that fit the surrounding system. That is the broad codebase-awareness problem.
When boundaries, contracts, tests, types, static analysis, and review comments all point back to design intent, they deepen that awareness and guide the next action. When those signals are hidden, noisy, or disconnected, the agent may still write plausible code while missing the system relationship that makes the change correct: it can cross layers, loop on the wrong fix, suppress errors, stop too early, or optimize for “green” without preserving the architecture.
When architecture separates what from how, humans can review behavior, contracts, boundaries, and design intent while agents use TDD to grind through implementation details. When that separation is weak, every AI-generated diff asks reviewers to inspect both intent and mechanics. That is the review-overload problem.
So “context routing” does not add another category to the list. It names the common structure underneath them: reliability depends on whether the codebase routes the agent toward the context needed to make the right change.
4. Read the Action the Agent Just Took
Every code modification produces a diff. It also produces a real context-routing trace.
To complete the task, the agent had to route itself through the codebase. It searched for entry points, opened files, followed names, tests, imports, comments, errors, types, and conventions, then chose one place to patch instead of another. That route is not an abstraction. It is the actual path by which the agent discovered context, selected a modification point, interpreted feedback, and decided the task was done.
Right after the task is finished, that routing trace is still fresh. The agent still has a high-resolution map of how the routing worked in practice: which signals helped it find the right files, which names or tests pointed in the right direction, which conventions made the next step obvious, which paths went nowhere, which boundary was hard to see, and where placement or ownership felt ambiguous.
That makes post-task reflection unusually valuable. It can ask three concrete questions while the evidence is still available:
- Did the codebase provide clear routing information for this change?
- Did context collection receive enough help from names, tests, docs, types, errors, and local structure?
- Did the model and harness notice and use those routing signals, or did they wander, over-read, under-read, or take a shortcut?
Human development workflows usually preserve the diff and discard this route. A pull request shows what changed. It rarely shows how the modifier found the change location, what misleading paths were explored, which abstractions were hard to discover, or which boundaries felt expensive to respect.
Agents create an opportunity to keep that context-routing trace before it evaporates.
This opportunity does not depend on a specific model weakness. Stronger models will still need to discover context. Better harnesses will still need routing signals to use. The interesting object is the interaction between the codebase, the model, and the harness: code structure, naming, tests, documentation, ownership rules, module boundaries, tool design, and retrieval behavior all shape the route.
When reflection repairs those routing problems, it improves the next modification. Clearer locality helps the next agent find the relevant context faster. Clearer boundaries help it avoid shortcuts. Clearer ownership helps it place new capability where the design expects it. That is why the agent’s struggle to gather context is telemetry: it reveals how the codebase can become easier for future agents to understand and modify reliably.
5. What Post-Task Design Reflection Checks
Post-task design reflection can stay small. Section 4 already established the main idea: every completed task leaves a context-routing trace. Reflection reads that trace and checks three concrete things.
5.1. Missing Path
Did the agent struggle to find context that should have been easy to reach?
This is a locality signal. The right file, test, registry, helper, or sibling change may already exist, but the codebase did not route the agent there clearly enough. The result is omission risk: related changes drift apart, existing capabilities get reimplemented, and tests that should guide the change stay disconnected from the work.
The repair is Locality Repair: add the smallest useful routing signal so the next modifier can find the existing destination. That might be a comment, registry entry, contract test, README note, naming adjustment, better file placement, or nearby pointer to the canonical implementation.
5.2. Unauthorized Shortcut
Did the agent complete the task by crossing a boundary the architecture meant to preserve?
This is a boundary signal. The patch may work locally while creating a new access path through internals, private state, implementation details, or the wrong layer. The result is boundary erosion: the system gains one more shortcut that future changes can copy.
The repair is Boundary Guard: move the change back through the intended contract and make that contract easier to see. That might mean clarifying an interface, adding a contract test, naming an owner, documenting a forbidden dependency, or moving the patch to the proper layer.
5.3. Unowned Capability
Did the task reveal a capability with no clear home?
This is a placement and ownership signal. The agent may need a cross-cutting helper, conversion, policy, or integration point, but the architecture gives no obvious answer for where it belongs. The result is duplication and drift: each future task can place the same capability locally.
The response is detect and report. Reflection should mark the ambiguous capability and surface the design decision: where should this live, who owns it, and what path should future changes follow?
6. Why Reflection Must Stay Small
Post-task design reflection is deliberately limited. It preserves execution fidelity to the existing design; it does not design the system on behalf of the team.
That limit is the point.
Many AI-caused reliability problems come from decisions being made implicitly. A patch introduces a new abstraction. A helper gains an accidental owner. A boundary moves because the direct edit was easier. A cross-cutting capability lands wherever the current task happened to be. The code works, but a design decision has been made without being named.
Reflection should prevent that silent transfer of authority. It gives the agent a narrow responsibility: recognize whether this task followed the design that already exists, and surface the places where a real design decision is required.
That is why the three checks in Section 5 are intentionally simple:
- Missing Path: repair discoverability when the destination already exists.
- Unauthorized Shortcut: guard an existing boundary when the patch crossed it.
- Unowned Capability: report the ownership gap when the destination has not been defined.
The first two can often produce a small fix. The third should usually produce a clear escalation. Reflection can say, “this capability needs a home,” but it should not invent that home as if placement were just another implementation detail.
This keeps the what / how boundary intact. Humans remain responsible for behavior, contracts, boundaries, ownership, and design intent. Agents can handle the how inside those constraints: implement, test, refine, and use TDD to grind through the mechanical details.
Reliable collaboration depends on that division of labor. The agent must learn to recognize where its implementation work ends and where human design authority begins. Post-task reflection is the practice that makes that boundary visible after every modification.
7. Why This Answers the Fear
The fear is that AI will mess up the codebase. A patch passes tests, the diff looks reasonable, and the immediate task is done. Over time, the next change becomes harder because the relevant context is harder to find: the right files are less obvious, the right boundary is less visible, the existing capability is harder to reuse, and the human reviewer has to reconstruct more of the system before trusting the change. That is the maintainability failure CMP is built to address: the codebase stops routing future modifiers toward all the context they need.
Post-task design reflection answers that fear by turning every modification into a small context-routing review.
It keeps the loop at the same scale as the risk. Missing Path repairs reduce the context cost of finding the next relevant file, test, helper, or sibling change. Boundary Guards keep existing design constraints visible at the point of change, so future agents can modify through the intended contract. Unowned Capability reports turn unclear placement into explicit design work, so future changes have a stable place to land and avoid duplicate code.
This also keeps the what / how boundary intact. The agent can still move fast through implementation: write code, run tests, refine, and handle mechanical details. Reflection keeps behavior, contracts, boundaries, ownership, and design intent in the human-reviewed layer, where maintainability decisions belong.
The rhythm matters most. Codebase maintainability erodes one modification at a time, so the repair loop should run one modification at a time as well. Put reflection at the end of every agentic task, while the context-routing trace is still fresh, and the system can lower the context cost before the next task follows the same weak path.
That is the promise: keep the codebase modifiable, preserve human design authority, and make the next agentic modification easier to route correctly.
Closing — Design in the Agent Era
Agentic engineering changes the unit of software design.
Design used to be judged mostly by how well it helped humans understand and change a system. Now it must also be judged by how well it helps agents discover the right context, follow the right constraints, and leave the system easier to modify after each change.
That makes post-task reflection more than a cleanup habit. It is a new design feedback loop for AI-maintained codebases. The agent’s path through the codebase becomes evidence. Its friction becomes a signal. Its uncertainty reveals where the system has not made its own design legible enough.
Post-task design reflection closes that loop one modification at a time.